
티스토리 뷰
프로세스 스케줄러
리눅스 커널에는 프로세스 스케줄러(Process Scheduler, 줄여서 스케줄러) 기능이 있는데 이 기능은 여러 개의 프로세스를 동시에 동작시키는 것처럼 보이게 한다. 이러한 스케줄러의 동작 방식은 다음과 같다.
- 하나의 CPU는 동시에 하나의 프로세스만 처리할 수 있다.
- 하나의 CPU에 여러 개의 프로세스를 실행해야 할 때는 각 프로세스를 적절한 시간으로 쪼개서(타임 슬라이스) 번갈아 처리한다.
프로세스 스케줄러 확인을 위한 테스트 프로그램 구현
테스트 프로그램 코드
// 필요한 헤더파일 및 상수 정의
#include <sys/types.h>
#include <sys/wait.h>
#include <time.h>
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <err.h>
#define NLOOP_FOR_ESTIMATION 1000000000UL
#define NSECS_PER_MSEC 1000000UL
#define NSECS_PER_SEC 1000000000UL
// 두 시간 구조체 사이의 시간 차이를 나노초 단위로 계산하는 함수
static inline long diff_nsec(struct timespec before, struct timespec after)
{
return ((after.tv_sec * NSECS_PER_SEC + after.tv_nsec)
- (before.tv_sec * NSECS_PER_SEC + before.tv_nsec));
}
// CPU 부하 작업을 수행하여 1밀리초 단위로 루프 실행 횟수를 추정하는 함수
// 'clock_gettime' 함수를 사용하여 시간을 측정하고, 루프를 실행하면서 시간 차이를 구해서 계산량을 추정한다.
static unsigned long loops_per_msec()
{
struct timespec before, after;
// CLOCK_MONOTONIC: 단조 시계로 특정시간부터 흐른 시간을 측정(일반적으로 부팅 이후 시간)
clock_gettime(CLOCK_MONOTONIC, &before);
unsigned long i; // unsigned: 음의 부호(-)를 붙이지 않고 0 이상의 값만 표현하겠다는 의미
for (i = 0; i < NLOOP_FOR_ESTIMATION; i++)
;
clock_gettime(CLOCK_MONOTONIC, &after);
int ret;
return NLOOP_FOR_ESTIMATION * NSECS_PER_MSEC / diff_nsec(before, after);
}
// 주어진 횟수만큼 아무런 일을 하지 않는 루프를 실행하여 CPU 부하 작업을 시뮬레이션한다.
// 인라인 함수는 함수 호출 시 그 자리에 인라인 함수 코드 자체가 안으로 들어간다.
static inline void load(unsigned long nloop)
{
unsigned long i;
for (i = 0; i < nloop; i++)
;
}
// 자식 프로세스에서 수행되는 함수이다.
// 주어진 횟수(nrecord)만큼 load 함수를 호출하고, clock_gettime 함수를 사용하여 시간을 기록한다.
// 그리고 시간 정보와 작업 진행 상황을 출력한다.
static void child_fn(int id, struct timespec *buf, int nrecord, unsigned long nloop_per_resol, struct timespec start)
{
int i;
for (i = 0; i < nrecord; i++) {
struct timespec ts;
// CPU 부하 작업을 시뮬레이션하고 작업 시간 측정하여 버퍼에 저장
load(nloop_per_resol);
clock_gettime(CLOCK_MONOTONIC, &ts);
buf[i] = ts;
}
// 자식 프로세스에서 작업 시작 시간부터 현재 작업 시간까지의 경과 시간을 밀리초 단위로 출력하고,
// 또한 현재 작업의 진행 상황을 백분율로 출력한다.
for (i = 0; i < nrecord; i++) {
printf("%d\t%ld\t%d\n", id, diff_nsec(start, buf[i]) / NSECS_PER_MSEC, (i + 1) * 100 / nrecord);
}
exit(EXIT_SUCCESS);
}
// 부모 프로세스에서 수행되는 함수
// 생성한 자식 프로세스들이 종료될 때까지 대기하는 역할을 한다.
static void parent_fn(int nproc)
{
int i;
for (i = 0; i < nproc; i++)
wait(NULL);
}
static pid_t *pids;
// 프로그램의 진입점
// 명령행 인수를 통해 자식 프로세스의 개수, 총 실행 시간, 해상도를 입력받는다.
// 해당 값들을 검증한 후 자식 프로세스를 생성하고 관리한다.
int main(int argc, char *argv[])
{
int ret = EXIT_FAILURE;
if (argc < 4) {
fprintf(stderr, "usage: %s <nproc> <total[ms]> <resolution[ms]>\n", argv[0]);
exit(EXIT_FAILURE);
}
int nproc = atoi(argv[1]); // 문자열을 정수로 변환하는 함수, 자식 프로세스 개수
int total = atoi(argv[2]); // 총 실행 시간
int resol = atoi(argv[3]); // 해상도
if (nproc < 1) {
fprintf(stderr, "<nproc>(%d) should be >= 1\n", nproc);
exit(EXIT_FAILURE);
}
if (total < 1) {
fprintf(stderr, "<total>(%d) should be >= 1\n", total);
exit(EXIT_FAILURE);
}
if (resol < 1) {
fprintf(stderr, "<resol>(%d) should be >= 1\n", resol);
exit(EXIT_FAILURE);
}
// total을 resol로 나눌 때 나머지가 생기면 작업 분배에 문제가 생길 수 있음
if (total % resol) {
fprintf(stderr, "<total>(%d) should be multiple of <resolution>(%d)\n", total, resol);
exit(EXIT_FAILURE);
}
// 자식 프로세스들의 정보를 기록할 버퍼를 할당하고, 작업량을 추정하는 loops_per_msec 함수를 호출한다.
int nrecord = total / resol;
// sizeof 함수는 데이터 타입 또는 변수의 크기를 바이트 단위로 반환하는 연산자
// malloc(memory allocation) 함수는 동적 메모리 할당을 위해 사용되는 함수
struct timespec *logbuf = malloc(nrecord * sizeof(struct timespec));
if (!logbuf)
err(EXIT_FAILURE, "malloc(logbuf) failed");
puts("estimating workload which taskes just one millisecond");
unsigned long nloop_per_resol = loops_per_msec() * resol;
puts("end estimation");
// 자식 프로세스 정보를 저장할 배열 할당
pids = malloc(nproc * sizeof(pid_t));
if (pids == NULL) {
warn("malloc(pids) failed");
goto free_logbuf;
}
// 작업 시작 시간 기록
struct timespec start;
clock_gettime(CLOCK_MONOTONIC, &start);
int i, ncreated;
// 자식 프로세스 생성 및 실행
for (i = 0, ncreated = 0; i < nproc; i++, ncreated++) {
pids[i] = fork();
if (pids[i] < 0) {
goto wait_children;
}
else if (pids[i] == 0) {
// 자식 프로세스
child_fn(i, logbuf, nrecord, nloop_per_resol, start);
/* shouldn't reach here */
}
}
ret = EXIT_SUCCESS;
// 자식 프로세스 종료 대기
wait_children:
if (ret == EXIT_FAILURE)
for (i = 0; i < ncreated; i++)
if (kill(pids[i], SIGINT) < 0)
warn("kill(%d) failed", pids[i]);
for (i = 0; i < ncreated; i++)
if (wait(NULL) < 0)
warn("wait() failed");
// 메모리 해제
ree_pids:
free(pids); // 할당한 자식 프로세스 배열 메모리 해제
free_logbuf:
free(logbuf); // 할당한 시간 정보 버퍼 메모리 해제
exit(ret); // 프로그램 종료
}
- diff_nsec 함수: 두 시간 간의 시간 차리를 나노초 단위로 계산한다.
- loops_per_msec 함수: CPU 부하 작업을 통해 1밀리초 단위로 루프 실행 횟수를 추정한다.
- load 함수: 주어진 횟수만큼 아무런 작업을 하지 않는 루프를 실행하여 CPU 부하 작업을 시뮬레이션한다.
- child_fn 함수: 자식 프로세스에서 실행되며, 주어진 횟수만큼 작업을 수행하고 시간 정보를 기록하여 출력한다.
- parent_fn 함수: 부모 프로세스에서 실행되며, 생성한 자식 프로세스들이 종료될 때까지 대기한다.
- main 함수: 프로그램 진입점으로, 명령행 인수를 받아 자식 프로세스 개수, 총 실행 시간, 해상도를 입력 받고, 이에 따라 자식 프로세스를 생성하고 관리한다.
중요 포인트는 CPU 시간을 1밀리초 단위로 사용 처리에 필요한 계산량을 추정하고 있는 loops_per_msec() 함수이다. loops_per_msec() 함수는 최초에 적당한 횟수(NLOOP_FOR_ESTIMATION)만큼 아무것도 하지 않는 루프를 돌려 필요한 시간을 측정한다. 그리고 NLOOP_FOR_ESTIMATION을 소요한 시간으로 나누면, 즉 몇 번 루프를 돌렸을 대 1밀리초가 걸리는지 추정할 수 있다.
스케줄러 동작 확인
taskset -c 0 ./sched <n> <total> <resol>
n total resol
1 100 1
2 100 1
4 100 1
OS에서 제공하는 taskset 명령어를 이용하여 '-c' 옵션으로 논리 CPU를 지정하고 프로그램을 동작하게 할 수 있다. 위 명령은 논리 CPU 0에서만 sched 프로그램을 실행하도록 제한한 것이다. 이제 첫 번째 인자인 자식 프로세스를 1, 2, 4개로 넘겨주어 테스트를 진행해보자.
동작 프로세스가 1개인 경우

동작 프로세스가 2개인 경우

동작 프로세스가 4개인 경우

각 프로세스는 논리 CPU를 사용하고 있는 동안에만 처리가 진행되며 그 이외의 시간, 즉 논리 CPU에 다른 프로세스가 동작 중일 때에는 처리가 진행되지 않는다. 즉, 특정 순간에 논리 CPU에서 동작하는 프로세스는 1개뿐이다. 따라서 프로세스 수가 늘어남에 따라 점점 처리 완료까지 걸린 시간이 2배, 4배로 비례하여 증가하는 것을 확인할 수 있다.
컨텍스트 스위치
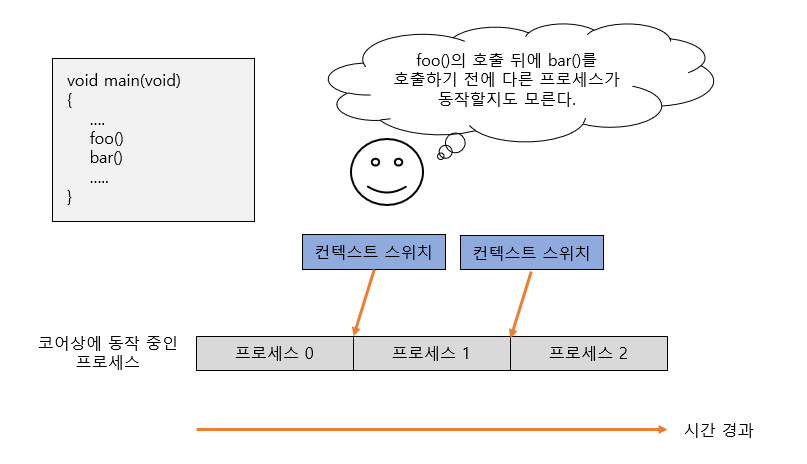
논리 CPU 상에서 동작하는 프로세스가 바뀌는 것을 컨텍스트 스위치(Context Switch)라고 부른다. 위 사진은 프로세스 0과 프로세스 1이 존재할 대 타임 슬라이스 타이밍에서 컨텍스트 스위치가 발생하는 모습이다.
컨텍스트 스위치는 프로세스가 어떤 프로그램을 수행 중이더라도 타임 슬라이스를 모두 소비하면 발생하기 때문에 위처럼 foo() 함수 다음에 bar() 함수가 실행될 것이라고 보장할 수 없다. 따라서 어떤 프로세스의 처리 시간이 예상보다 오래 걸렸을 경우 처리 자체에 문제가 있는 것이라는 단순한 결론을 내리기 보다는 처리 중에 컨텍스트 스위치가 발생해서 다른 프로세스가 움직였을 가능성이 있다는 관점을 가질 수 있다.
프로세스의 상태
| 상태 | 의미 |
| 실행 상태 | 현재 논리 CPU를 사용하고 있다. |
| 실행 대기 상태 | CPU 시간이 할당되기를 기다리고 있다. |
| 슬립 상태 | 이벤트가 발생하기를 기다리고 있으며, 이벤트 발생까지는 CPU 시간을 사용하지 않는다. |
| 좀비 상태 | 프로세스가 종료한 뒤 부모 프로세스가 종료 상태를 인식할 때까지 기다리고 있는다. |
프로세스에는 위 표처럼 다양한 상태를 갖는다. 물론 더 많은 상태가 있지만 위 정도로 충분하고, 슬립 상태에서 기다리고 있는 이벤트의 예로는 다음과 같다.
- 정해진 시간이 경과하는 것을 기다린다.
- 키보드나 마우스 같은 사용자 입력을 기다린다.
- HDD나 SSD 같은 저장 장치의 읽고 쓰기의 종료를 기다린다.
- 네트워크의 데이터 송수신의 종료를 기다린다.
ps ax
| STAT 필드의 첫 문자 | 상태 |
| R | 실행 상태 혹은 실행 대기 상태 |
| S 혹은 D | 슬립 상태. 시그널에 따라 실행 상태로 되돌아오는 것이 S. 그렇지 않은 것이 D |
| Z | 좀비 상태 |
각 프로세스의 상태는 위 명령어를 실행하여 확인할 수 있다. 출력되는 결과의 세 번째 필드인 STAT 필드의 첫 문자를 보면 알 수 있다.

자세히 보면 ps ax는 R이다. 이것은 이 프로그램이 프로세스의 상태를 출력하기 위해 동작 중이기 때문이다. 그리고 bash가 슬립 상태인 것은 사용자로부터 입력을 기다리고 있기 때문에 S로 표시되어 있다. 위 결과에서는 보이지 않지만 D 상태에 있는 프로세스는 일반적으로 수 밀리초 정도 지나면 다른 상태로 바뀌는데 장시간을 D 상태로 있다면 다음과 같은 원인을 생각해볼 수 있다.
- 스토리지의 I/O가 종료되지 않은 상태로 되어 있다.
- 커널 내에 뭔가 문제가 발생하고 있다.

프로세스는 위 그림처럼 생성부터 종료까지 CPU 시간을 필요한 만큼 계속해서 사용하고 종료하는 것이 아니라 살아있는 동안 실행 상태, 실행 가능 상태, 슬립 상태를 몇 번이고 오간다.
idle 상태
논리 CPU에는 idle 프로세스라고 하는 아무것도 하지 않는 특수한 프로세스가 동작한다. idle 프로세스의 가장 단순한 구현은 새로운 프로세스가 생성되거나 혹은 슬립 상태에 있는 프로세스가 깨어날 때까지 아무 의미 없는 루프를 하는데 이렇게 만들면 전력만 낭비하기 때문에 그 대신 CPU의 특수한 명령을 이용하여 논리 CPU를 휴식 상태로 만들어 하나 이상의 프로세스가 실행 가능한 상태가 될 때까지 소비 전력을 낮춰 대기 상태로 만든다.
노트북이나 스마트폰으로 아무것도 하지 않는 상태일 때 배터리가 오래가는 이유가 바로 논리 CPU가 소비 전력이 낮은 idle 상태로 오래 있기 때문이다.
while True:
pass
가장 오른쪽의 %idle 필드가 1초간 어느 정도 idle 상태였는지를 표시하는 수치이다. 다른 프로세스는 거의 100%에 가까운 것을 보니 시스템 전체가 CPU 시간을 거의 사용하지 않았음을 확인할 수 있고, 논리 CPU 0에 위처럼 무한로프를 도는 파이썬 프로그램을 실행했을 때는 CPU 0만 %idle이 0인 것을 보아 loop.py 프로그램이 계속해서 동작하고 있는 것을 확인할 수 있다.
여러 가지 상태 변환
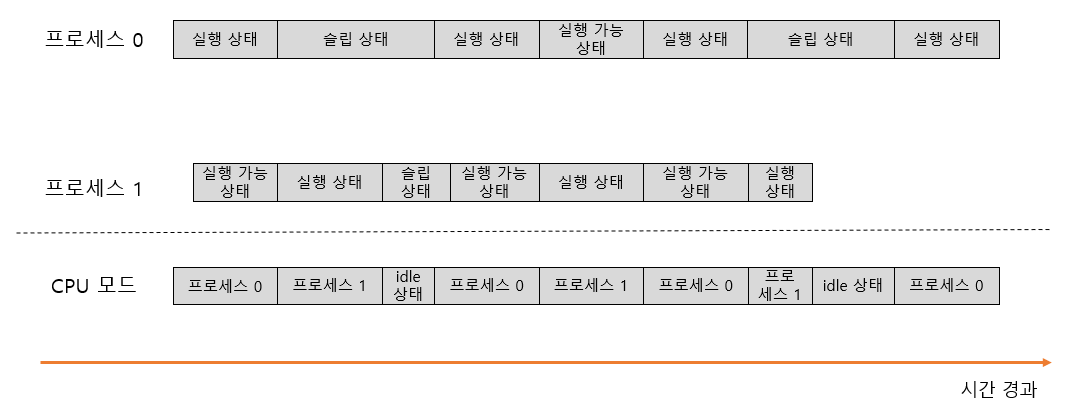
실제 시스템에서는 다양한 프로세스가 각각의 처리에 따라, 다양한 상태를 거치게 된다. 이에 따라 논리 CPU에 어느 프로세스가 움직이고 있는가도 변한다. 논리 CPU에 여러 프로세스가 있는 경우 위 그림처럼 논리 CPU가 움직이는 것을 확인할 수 있다. 복잡하지만 여기서 중요한 두 가지를 기억하면 된다.
- 논리 CPU로 한 번에 실행할 수 있는 프로세스는 1개뿐이다.
- 슬립 상태에서는 CPU 시간을 사용하지 않는다.
스루풋과 레이턴시
각종 처리의 성능지표인 스루풋과 레이턴시는 다음과 같다.
- 스루풋
- 완료한 프로세스의 수 / 경과시간
- 단위 시간당 처리된 일의 양으로 높을수록 좋다.
- 레이턴시
- 처리 종료 시간- 처리 시작 시간
- 각각의 처리가 시작부터 종료까지의 경과된 시간으로 짧을수록 좋다.
스루풋
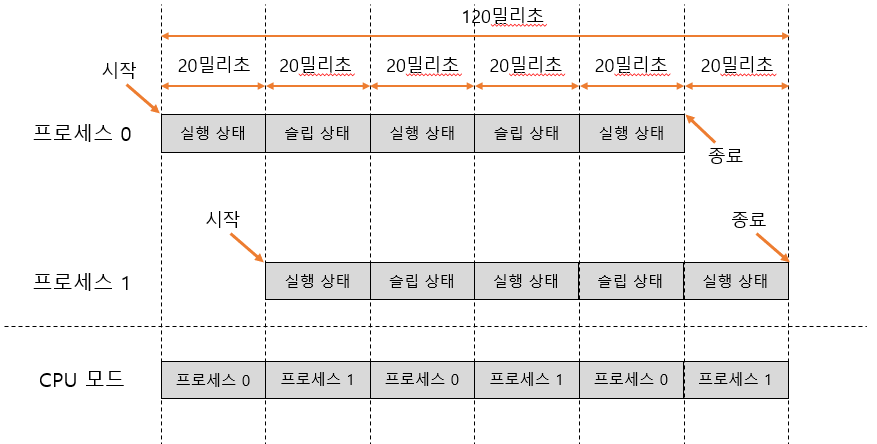
스루풋은 기본적으로 논리 CPU의 연산 리소스를 사용하면 할수록 높아진다. 즉, CPU의 idle 상태가 적어질수록 높아진다. 위 그림은 논리 CPU를 사용했다가 슬립했다가를 반복하는 프로세스 2개가 있는 경우 프로세스와 논리 CPU의 상태를 나타낸 것이다. 이 때 논리 CPU는 idle 상태가 되지 않으며 스루풋은 다음과 같이 계산할 수 있다.
- 스루풋 = 2프로세스 / 120밀리초 = 2프로세스 / 0.12초 = 16.7프로세스 / 1초
위 결과는 컨텍스트 스위칭으로 인한 비용을 고려하지 않은 경우이다. 이제 컨텍스트 스위칭과 레이턴시까지 고려하여 처리하면 어떻게 되는지 살펴보자.
프로세스 0의 스루풋, 평균 레이턴시
- 100밀리초 동안 1개의 프로세스가 완료된 경우
- 스루풋 = 1프로세스 / 100밀리초 = 1프로세스 / 0.1초 = 10프로세스 / 1초
- 평균 레이턴스 = 프로세스 0의 레이턴시 = 100밀리초
프로세스 0 ~ 1의 스루풋, 평균 레이턴시
- 200밀리초 동안 2개의 프로세스가 완료된 경우
- 스루풋 = 2프로세스 / 0.2초 = 10프로세스 / 1초
- 평균 레이턴시 = 프로세스 0과 프로세스 1의 레이턴시 = 200밀리초
프로세스 0 ~ 3의 스루풋, 평균 레이턴시
- 400밀리초 동안 4개의 프로세스가 완료된 경우
- 스루풋 = 4프로세스 / 0.4초 = 10프로세스 / 1초
- 평균 레이턴시 = 프로세스 0 ~ 3의 레이턴시 = 400밀리초
결과
| 프로세스 수 | 스루풋(프로세스 / 초) | 평균 레이턴시(밀리초) |
| 1 | 10 | 100 |
| 2 | 10 | 200 |
| 4 | 10 | 400 |
여기에서 다음과 같은 점을 알 수 있다.
- 논리 CPU의 능력을 전부 활용, 즉 모든 논리 CPU가 idle 상태가 되지 않는 경우에는 프로세스 개수를 늘려도 스루풋은 변하지 않는다.
- 다른 말로 표현하면 %idle이 0인데도 프로세스를 계속 늘리면 컨텍스트 스위칭의 오버헤드 등의 증가로 인해 스루풋이 감소한다.
- 프로세스 수를 늘릴수록 레이턴시는 악화된다.
- 각 프로세스의 평균 레이턴시는 비슷하다.
논리 CPU가 여러 개일 때 스케줄링
논리 CPU가 여러 개일 때는 스케줄러 안의 논리 CPU를 여러 개 다루기 위해 로드밸런서(Load Balancer) 혹은 글로벌 스케줄러(Global Scheduler)라는 기능이 동작한다. 로드밸런서는 여러 개의 논리 CPU에 프로세스를 공평하게 분배해주는 역할을 한다. 프로세스를 할당받은 각 논리 CPU 안에서 1개의 논리 CPU가 있을 때와 마찬가지로 각 프로세스에 공평하게 CPU 시간을 분배한다.
프로세스 0의 스루풋, 평균 레이턴시
- 100밀리초 동안 1개의 프로세스가 완료된 경우
- 스루풋 = 1프로세스 / 100밀리초 = 1프로세스 / 0.1초 = 10프로세스 / 1초
- 평균 레이턴스 = 프로세스 0의 레이턴시 = 100밀리초
프로세스 0 ~ 1의 스루풋, 평균 레이턴시
- 200밀리초 동안 2개의 프로세스가 완료된 경우
- 스루풋 = 2프로세스 / 100밀리초 = 2프로세스 / 0.1초 = 20프로세스 / 1초
- 평균 레이턴시 = 프로세스 0과 프로세스 1의 레이턴시 = 100밀리초
프로세스 0 ~ 3의 스루풋, 평균 레이턴시
- 400밀리초 동안 4개의 프로세스가 완료된 경우
- 스루풋 = 4프로세스 / 200밀리초 = 4프로세스 / 0.2초 = 20프로세스 / 1초
- 평균 레이턴시 = 프로세스 0 ~ 3의 레이턴시 = 200밀리초
결과
| 프로세스 수 | 스루풋(프로세스 / 초) | 평균 레이턴시(밀리초) |
| 1 | 10 | 100 |
| 2 | 20 | 100 |
| 4 | 20 | 200 |
여기에서 다음과 같은 점을 알 수 있다.
- 1개의 CPU에 동시에 처리되는 프로세스는 1개이다.
- 여러 개의 프로세스가 실행 가능한 경우 각각의 프로세스를 적절한 길이의 시간(타임 슬라이스)마다 CPU에서 순차적으로 처리한다.
- 멀티코어 CPU 환경에서는 여러 개의 프로세스를 동시에 동작시키지 않으면 스루풋이 오르지 않는다. '코어가 n개 있으므로 성능이 n배'라고 말할 수 있는 것은 어디까지나 최선의 케이스인 경우이다.
- 단, 1개의 논리 CPU의 경우와 마찬가지로 프로세스 수를 논리 CPU 수보다 많게 하더라도 스루풋은 오르지 않는다.
경과 시간과 사용 시간

time 명령어를 통해 프로세스를 동작시키면 프로세스의 시작부터 종료까지의 시간 사이에 경과 시간과 사용 시간이라는 두 가지 수치를 얻을 수 있다.
- 경과 시간: 프로세스가 시작해서 종료할 때까지의 경과 시간이다. 스톱워치로 프로세스의 시작부터 종료가지 시간을 측정한 것이라고 보면 된다.
- 사용 시간: 프로세스가 실제로 논리 CPU를 사용한 시간이다.
논리 CPU 수 = 1, 프로세스 수 = 1

real의 값이 경과시간이다. 그 아래 있는 user와 sys의 수치를 더하면 사용시간이다. user의 값은 프로세스가 실행 중인 사용자 모드에서 CPU를 사용한 시간이다. 반대로 sys의 값은 프로세스의 실행 중에 사용자 모드의 처리로부터 호출된 커널이 시스템 콜을 실행한 시간이다. 대부분의 시간은 사용자 모드에서 루프를 처리하고 있기 때문에 sys의 값은 거의 0이 된다.
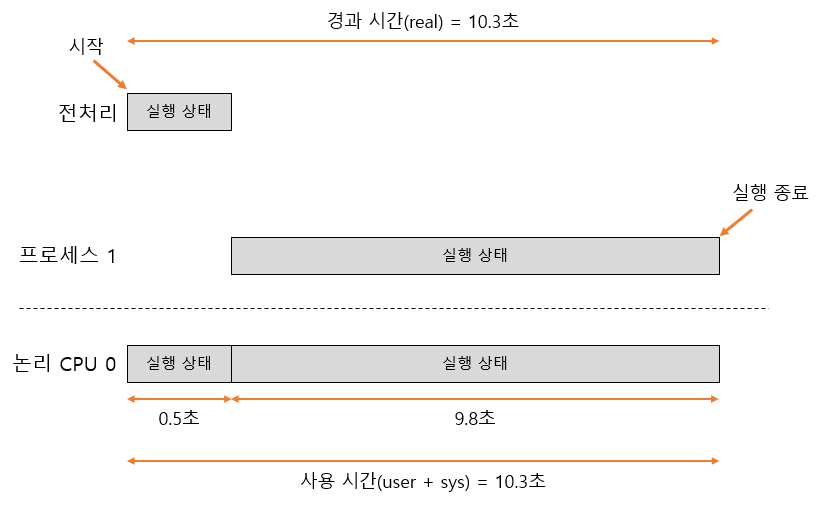
프로세스 종료까지 사용한 시간이 약 10.3초가 걸린 것에 비해 100%의 진행도를 얻기 위해서는 약 9.8초를 필요로 하고 있다. 이 두 시간의 차이는 실제 처리 전에 0.5초 정도의 CPU 시간을 사용하는 계산량을 측정하기 위해 하는 전처리(sched.c의 loops_per_msec() 함수)에 걸린 시간이다.
논리 CPU 수 = 2, 프로세스 수 = 4

경과 시간은 논리 CPU 수 = 1, 프로세스 수 = 1의 경우와 거의 비슷하지만, 사용 시간은 두 배가 되었다. 이는 2개의 프로세스는 각각 2개의 논리 CPU에 따로따로 실행이 가능하기 때문이다. 멀티코어의 시스템에서는 여러 CPU를 동시에 사용하고 있으므로 총합의 사용 시간은 당연히 더 길어질 수 있다.
- 경과 시간(real) = 11초
- 사용 시간 = 논리 CPU 0의 사용 시간 + 논리 CPU 2의 사용 시간 = (1.8 + 10.3) + 10.3 = 22.4초
우선순위 변경
nice의 '-n' 옵션으로 우선순위를 지정하여 특정 프로그램을 우선순위를 바꾼 상태로 실행할 수 있다. 소스를 수정하지 않고 실행 우선순위를 바꿀 수 있기 때문에 편리한 방법이다. 프로세스의 실행 우선순위를 -19부터 20까지 설정할 수 있고, 기본값은 0이다. -19가 가장 우선순위가 높고 20이 가장 낮다. 우선순위가 높은 프로세스는 평균보다 CPU 시간을 더 많이 배정받고, 우선순위가 낮은 프로세스는 평균보다 적게 CPU 시간을 받는다. 우선순위를 내리는 것은 리눅스 사용자 계정 누구라도 가능하지만 우선순위를 높이는 것은 root 권한을 가지고 있는 슈퍼유저뿐이다.
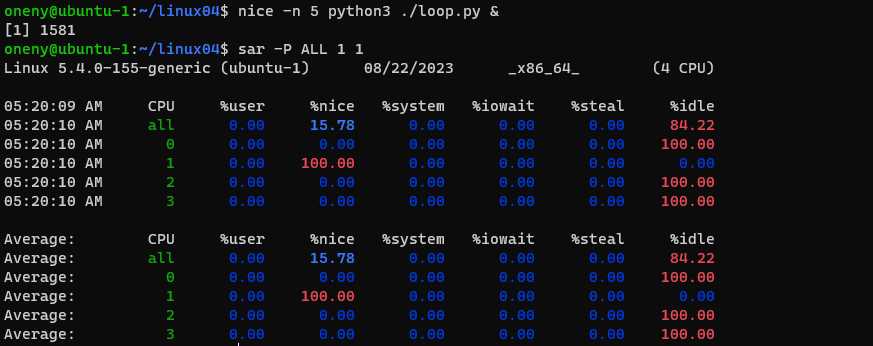
nice를 사용하지 않을 경우에는 %user가 100이었던 것에 비해서 nice를 사용한 경우에는 %nice가 100으로 되어있다.
'교육 및 책 > 실습과 그림으로 배우는 리눅스 구조' 카테고리의 다른 글
| 프로세스 관리 (0) | 2023.08.04 |
|---|---|
| 사용자 모드로 구현되는 기능(시스템 콜) (0) | 2023.08.03 |
- Total
- Today
- Yesterday
- 낙관적 락
- nginx
- nginx configuration
- 분산 락
- TDD
- sql
- 트랜잭션
- mysql
- annotation
- 카프카
- redis session
- 넥스트스탭
- pessimistic lock
- Java
- transaction
- postgresql
- jvm 메모리 구조
- EKS
- 람다
- 구름톤 챌린지
- socket
- spring session
- NeXTSTEP
- Redisson
- Kafka
- Synchronized
- spring webflux
- 구름톤챌린지
- 비관적 락
- mdcfilter
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |