
티스토리 뷰
프로세스 생성의 목적
리눅스에서는 두 가지 목적으로 프로세스를 생성한다.
- 목적 1: 같은 프로그램의 처리를 여러 개의 프로세스가 나눠서 처리한다. 예를 들어, 웹 서버처럼 요청이 여러 개 들어왔을 때 동시에 처리해야 하는 경우
- 목적 2: 전혀 다른 프로그램을 생성한다. 예를 들어, bash로부터 각종 프로그램을 새로 생성하는 경우
위의 생성 목적에 fork()와 execve() 함수를 사용한다(시스템 내부에서는 clone()과 execve() 시스템 콜을 호출한다.)
fork() 함수
위 목적1에는 fork() 함수만을 사용한다. fork() 함수를 실행하면 실행한 프로세스와 함께 새로운 프로세스가 1개 생성된다. 생성 전의 프로세스를 부모 프로세스(parent process), 새롭게 생성된 프로세스를 자식 프로세스(child process)라 부른다. 프로세스를 생성하는 순서를 다음과 같다.

- 자식 프로세스용 메모리 영역을 작성하고 거기에 부모 프로세스의 메모리를 복사한다.
- fork() 함수의 리턴값이 각기 다른 것을 이용하여 부모 프로세스와 자식 프로세스가 서로 다른 코드를 실행하도록 분기한다.
fork() 함수 사용하기
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
#include <err.h>
static void child()
{
printf("I'm child! my pid is %d.\n", getpid());
exit(EXIT_SUCCESS);
}
static void parent(pid_t pid_c)
{
printf("I'm parent! my pid is %d and the pid of my child is %d.\n", getpid(), pid_c);
exit(EXIT_SUCCESS);
}
int main(void)
{
pid_t ret;
ret = fork(); // fork() 함수를 리턴(반환)할 때 부모 프로세스는 자신 프로세스의 프로세스 ID를, 자식 프로세스는 0을 리턴한다.
if (ret == -1)
err(EXIT_FAILURE, "fork() failed");
if (ret == 0) {
// child process came here because fork() returns 0 for child process
child();
} else {
// parent process came here because fork() returns the pid of newly created child process (> 1)
parent(ret);
}
// shouldn't reach here
err(EXIT_FAILURE, "shouldn't reach here");
}프로세스를 새로 만들어 부모 프로세스는 자신의 프로세스 ID와 자식 프로세스의 프로세스를 출력한 뒤 종료하는 코드를 작성했다. fork() 함수를 리턴(반환)할 때 부모 프로세스는 자식 프로세스의 프로세스 ID를, 자식 프로세스는 0을 리턴한다. 이를 이용하여 부모 프로세스와 자식 프로세스의 처리를 나눠서 실행한다.

프로세스 ID가 1421인 프로세스가 분기 실행되어 부모 프로세스에게 프로세스 ID 1422번의 자식 프로세스가 생성되었단느 점뿐만 아니라 fork() 함수 실행 뒤에 두 프로세스의 처리가 분기되어 실행되고 있음을 알 수 있다.
execve() 함수
전혀 다른 프로그램을 생성할 때는 execve() 함수를 사용한다. 커널이 각각의 프로세스를 실행하기까지의 과정은 다음과 같다.
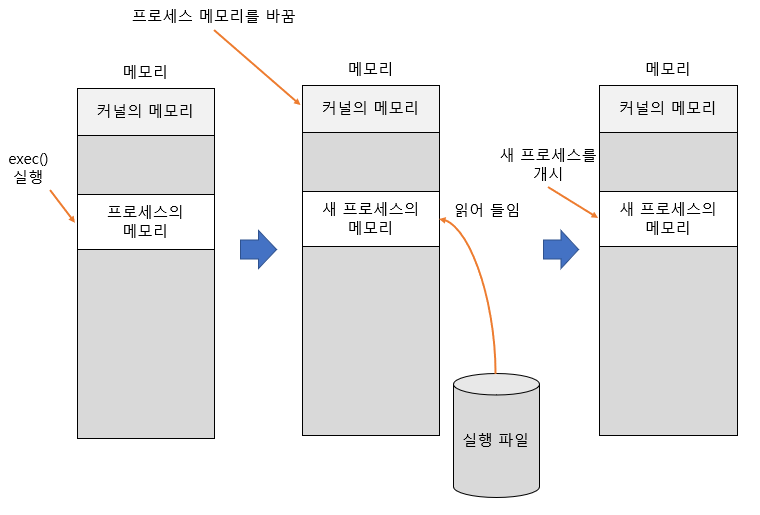
- 실행 파일을 읽은 다음 프로세스의 메모리 맵에 필요한 정보를 읽어 들인다.
- 현재 프로세스의 메모리를 새로운 프로세스의 데이터로 덮어쓴다.
- 새로운 프로세스의 첫 번째 명령부터 실행한다.
위 과정을 살펴보면 전혀 다른 프로그램을 생성하는 경우 프로세스의 수가 증가하는 것이 아니라 기존의 프로세스를 별도의 프로세스로 변경하는 방식으로 수행한다는 것을 알 수 있다.
프로그램 전체 실행 순서
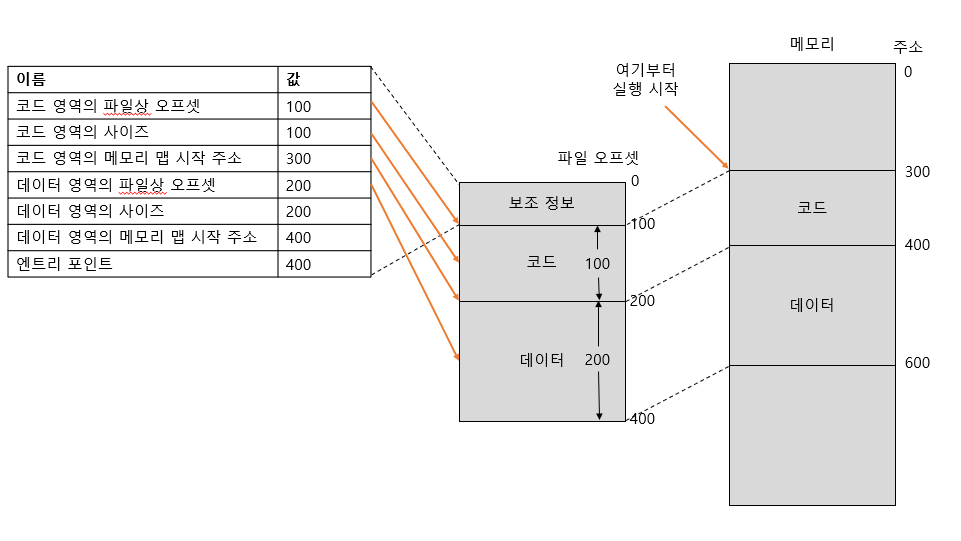
좀 더 구체적인 전체 순서에 대해서 알아보자. 일단, 실행 파일을 읽고 프로세스의 메모리 맵에 필요한 정보를 읽어 들어들이는데 실행 파일은 프로세스의 실행 중에 사용하는 코드와 데이터 이외에도 다음과 같은 정보가 필요하다.
- 코드를 포함한 데이터 영역의 파일상 오프셋, 사이즈, 메모리 맵 시작 주소
- 코드 외의 변수 등에서의 데이터 영역에 대한 같은 정보(오프셋, 사이즈, 메모리 맵 시작 주소)
- 최초로 실행할 명령의 메모리 주소(엔트리 포인트: entry point)
코드 영역과 데이터 영역의 메모리 맵 시작 주소가 필요한 이유는 CPU에서 실행되는 기계언어 명령은 고급언어로 쓰인 소스코드와는 다르게 특정 메모리 주소를 지정할 필요가 있기 때문이다.
c = a + b
메모리 주소를 직접 조작하는 기계어로 변환(컴파일)
load m100 r0 <-- 0번 레지스터(r0)에 메모리 주소 100(변수 a)의 값을 읽어 들인다.
load m200 r1 <-- 1번 레지스터(r1)에 메모리 주소 200(변수 b)의 값을 읽어 들인다.
add r0 r1 r2 <-- r0의 값과 r1의 값을 더한 결과를 2번 레지스터(r2)에 저장한다.
store r2 m300 <-- 2번 레지스터(r2)의 값을 메모리 주소 300(변수 c)에 쓴다.
위처럼 고급언어로 c = a + b와 같은 코드를 적고 기계언어로 바꾸면 그 아래처럼 메모리 주소를 직접 조작하는 명령으로 변환(컴파일)된다. 위 그림처럼 엔프리 포인트(entry point)에서부터 프로그램을 실행하면 완료된다.

리눅스의 실행 파일은 실제로는 이렇게 단순하기 보다는 ELF(Executable Linkable Format)라는 형식을 사용한다. ELF 형식의 각종 정보는 'readelf' 명령어로 자세히 살펴볼 수 있다. /bin/sleep의 정보를 예시로 -h 옵션을 지정하여 시작 주소를 얻을 수 있다. Entry point address 줄의 0x2858이 해당 프로그램의 엔트리 포인트로 코드와 데이터 영역의 파일상의 오프셋, 사이즈, 메모리 맵 시작 주소를 얻으려면 -S 옵션을 사용하면 된다.
참고: ELF(Executable and Linkable Format)
유닉스 계열 운영체제의 실행, 오브젝트 파일, 공유 라이브러리, 또는 코어 덤프를 할수 있게 하는 바이너리 파일이다. 간단히, 실행 파일이다.
출처: 나무위키 - ELF
/bin/sleep의 정보
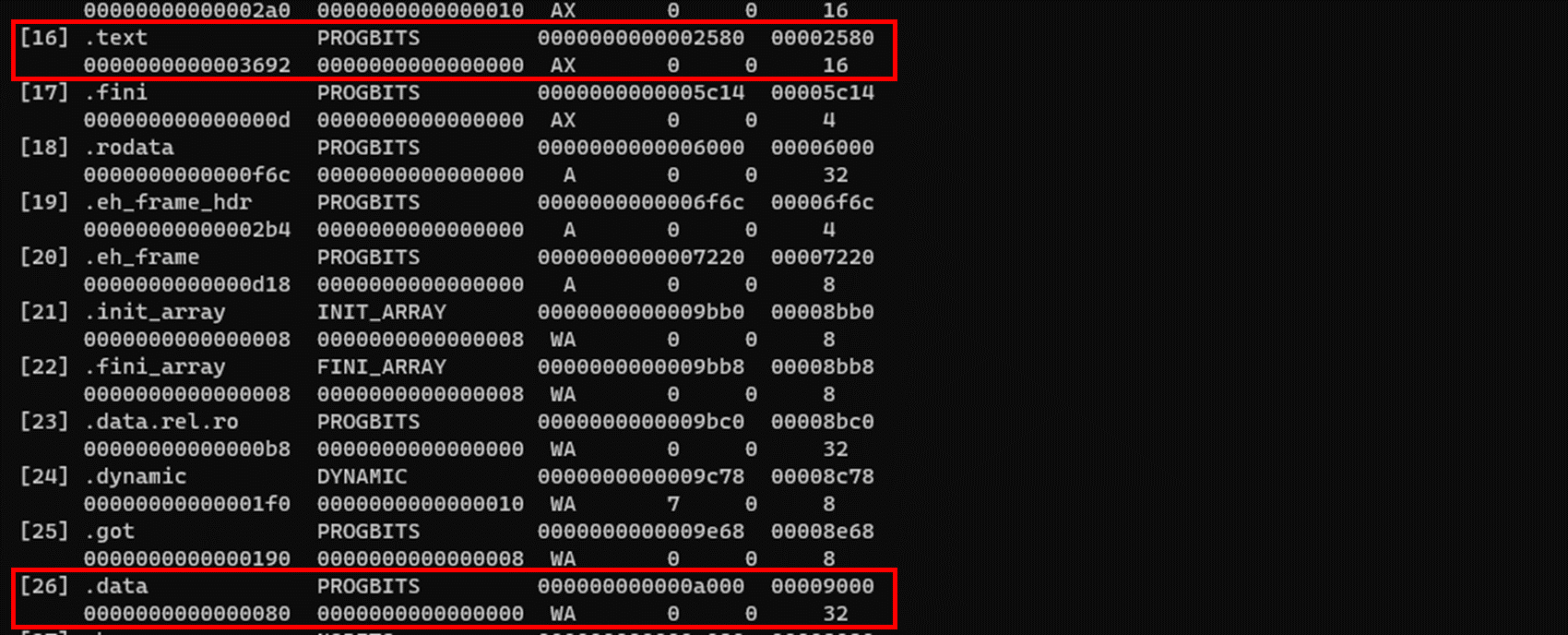
여러 내용이 출력되었는데 아래 사항만 이해하면 충분하다.
- 출력된 내용은 두 줄이 하나의 정보 세트이다.
- 수치는 전부 16진수이다.
- 세트 중 첫 줄의 두 번째 필드가 .text이면 코드 영역의 정보를, .data면 데이터 영역의 정보를 의미한다.
- 세트의 다음 위치를 보면 정보를 알 수 있다.
- 메모리 맵 시작 주소: 첫 줄의 네 번째 필드
- 파일상의 오프셋: 첫 줄의 다섯 번째 필드
- 사이즈: 둘째 줄의 첫 번째 필드
| 이름 | 값 |
| 코드 영역의 파일상 오프셋 | 0x2580 |
| 코드 영역의 사이즈 | 0x3692 |
| 코드 영역의 메모리 맵 시작 주소 | 0x2580 |
| 데이터 영역의 파일상 오프셋 | 0x9000 |
| 데이터 영역의 사이즈 | 0x80 |
| 데이터 영역의 메모리 맵 시작 주소 | 0xa000 |
| 엔트리 포인 | 0x2850 |
이 내용을 기반으로 /bin/sleep의 정보를 정리하면 위와 같다. 또한, 프로그램 실행 시에 작성된 프로세스 메모리 맵은 /proc/(pid)/maps 파일을 통해 알 수 있다.
fork and exec
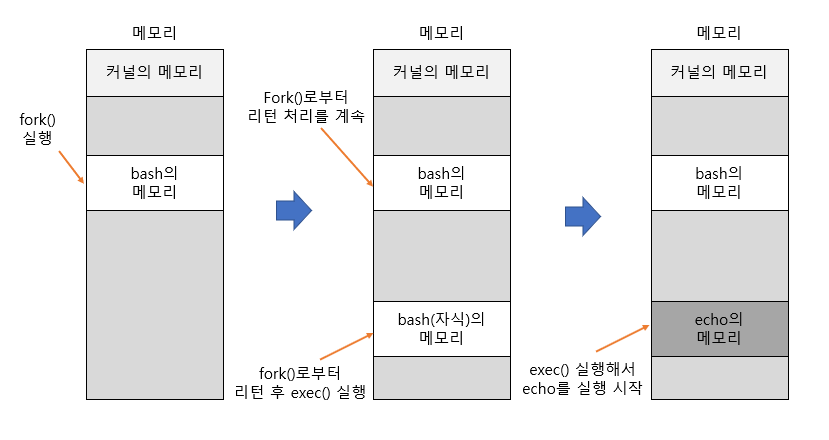
전혀 다른 프로세스를 새로 생성할 때는 부모가 될 프로세스로부터 fork() 함수를 호출한 다음 돌아온 자식 프로세스가 exec() 함수를 호출하는 방식, 즉 fork and exec이라는 방식을 주로 사용한다. 위 그림이 bash가 echo를 생성하는 모습이다.
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
#include <err.h>
static void child()
{
char *args[] = { "/bin/echo", "hello", NULL };
printf("I'm child! my pid is %d.\n", getpid());
fflush(stdout); // 표준 출력 버퍼를 비워라. 즉, 버퍼에 저장된 내용을 출력하라는 의미
execve("/bin/echo", args, NULL); // 다른 프로그램(echo)으로 실행
err(EXIT_FAILURE, "exec() failed");
}
static void parent(pid_t pid_c)
{
printf("I'm parent! my pid is %d and the pid of my child is %d.\n", getpid(), pid_c);
exit(EXIT_SUCCESS);
}
int main(void)
{
pid_t ret;
ret = fork();
if (ret == -1)
err(EXIT_FAILURE, "fork() failed");
if (ret == 0) {
// child process came here because fork() returns 0 for child process
child();
} else {
// parent process came here because fork() returns the pid of newly created child process (> 1)
parent(ret);
}
// shouldn't reach here
err(EXIT_FAILURE, "shouldn't reach here");
}
부모 프로세스는 echo hello 프로그램을 생성한 뒤 자신의 프로세스 ID와 자식 프로세스의 프로세스 ID를 출력하고 종료한다. 자식 프로세스는 자신의 프로세스 ID를 출력하고 종료한다.
종료 처리

프로그램 종료는 _exit() 함수를 사용한다(내부에서는 exit_group() 시스템 콜을 호출한다). 이것을 이용하면 위 그림처럼 프로세스에 할당된 메모리 전부를 회수한다. 직접 _exit()를 호출하는 일은 매우 드물며, 보통 표준 C 라이브러리의 exit() 함수를 호출해서 종료한다. 이러한 경우 표준 C 라이브러리는 자신의 종료 처리를 전부 수행한 뒤에 _exit() 함수를 호출한다. main() 함수로부터 리턴된 경우도 같은 동작을 한다.
'교육 및 책 > 실습과 그림으로 배우는 리눅스 구조' 카테고리의 다른 글
| 프로세스 스케줄 (0) | 2023.08.22 |
|---|---|
| 사용자 모드로 구현되는 기능(시스템 콜) (0) | 2023.08.03 |
- Total
- Today
- Yesterday
- annotation
- 낙관적 락
- mdcfilter
- mysql
- 넥스트스탭
- transaction
- socket
- Synchronized
- 비관적 락
- sql
- redis session
- NeXTSTEP
- 구름톤 챌린지
- jvm 메모리 구조
- 분산 락
- postgresql
- 카프카
- EKS
- Kafka
- spring session
- Java
- nginx configuration
- nginx
- pessimistic lock
- Redisson
- 람다
- TDD
- 구름톤챌린지
- spring webflux
- 트랜잭션
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |