
티스토리 뷰
LRU 알고리즘
LRU 알고리즘은 페이지 교체 알고리즘 중 하나로 사용되는 가장 오랫동안 참조되지 않은 페이지를 교체하는 기법을 말한다.
캐시가 사용하는 리소스의 양은 제한되어 있고, 캐시는 제한된 리소스 내에서 데이터를 빠르게 저장하고 접근할 수 있어야 한다. 이러한 LRU 알고리즘은 다음과 같은 특징을 갖는다.
장점
- 빠른 액세스: 가장 최근에 사용한 요소부터 가장 적게 사용한 요소까지 정렬된다. 따라서 요소에 접근할 경우, O(n)의 시간 복잡도를 가진다.
- 빠른 Update: 하나의 요소에 액세스할 때마다 업데이트되며, O(n)의 시간 복잡도를 가진다.
단점
- 많은 공간을 차지한다.
- N개의 요소를 저장하는 LRU는 N의 크기를 가지는 1개의 LinkedList(Queue)와 이를 추적하기 위한 N의 크기를 가지는 1개의 HashMap이 필요하다.
- 이는 O(n)의 복잡도를 가지지만, 2개의 데이터 구조를 사용해야 한다는 단점이 있다.
LRUCache 만들기
public class LRUCache<K, V> implements Cache<K, V> {
private final int capacity;
private final Map<K, Element<K, V>> elementMap;
private final LinkedList<Element<K, V>> elementsList;
public LRUCache(int capacity) {
this.capacity = capacity;
this.elementMap = new HashMap<>();
this.elementsList = new LinkedList<>();
}
@Override
public Optional<V> get(K key) {
Optional<V> result = Optional.empty();
if (containsKey(key)) {
Element<K, V> findElement = elementMap.get(key);
result = Optional.of(findElement.value);
elementsList.remove(findElement);
elementsList.addFirst(findElement);
}
return result;
}
@Override
public void put(K key, V value) {
if (containsKey(key)) { // 해당 key가 있으면 LinkedList에서 제거
elementsList.remove(elementMap.get(key));
} else { // 없는 경우 LinkedList의 사이즈가 capacity만큼 찬 경우
ensureCapacity();
}
Element<K, V> newElement = new Element<>(key, value);
elementMap.put(key, newElement);
elementsList.addFirst(newElement);
}
@Override
public boolean containsKey(K key) {
return elementMap.containsKey(key);
}
@Override
public int size() {
return elementsList.size();
}
public Optional<K> getLastRecentKey() {
return elementsList.size() > 0 ? Optional.of(elementsList.getFirst().key) : Optional.empty();
}
private boolean isSizeExceeded() {
return size() == capacity;
}
private void ensureCapacity() {
if (isSizeExceeded()) {
Element<K, V> removedElement = elementsList.removeLast();
elementMap.remove(removedElement.key);
}
}
protected static class Element<K, V> {
private final K key;
private final V value;
public Element(K key, V value) {
this.key = key;
this.value = value;
}
}
}get() 메서드
get() 메서드의 경우에는 HashMap에 key가 있는 경우에 가져와서 반환한다. 이 때, 액세스한 요소를 업데이트해주기 위해 LinkedList에서 해당 요소를 삭제하고 제일 앞에 요소를 다시 추가한다.
put() 메서드
요소를 넣는 과정에서 key가 있으면 LinkedList에서 key에 해당하는 value를 삭제하고, 없는 경우 LinkedList의 size가 capacity와 같으면 제일 마지막 요소를 제거해준다. 그리고 새로 넣을 요소를 생성하여 HashMap에 요소를 넣고, LinkedList에 제일 앞에 추가한다.
LRUCache를 이용하여 메모리를 직접 관리하는 캐시 만들기
메모리 정리하는 방법
메모리 누수는 겉으로 잘 드러나지 않아 시스템에 수년간 잠복하는 사례도 있다. 이런 누수는 철저한 코드 리뷰나 힙 프로파일러 같은 디버깅 도구를 동원해야만 발견되기도 한다. 그래서 이런
oneny.tistory.com
위 블로그에서 메모리를 정리하는 방법 중 세 번째 방법으로 LRU 알고리즘을 이용하여 직접 메모리를 관리할 수 있다고 소개한 적이 있다. 다른 방법들은 실제로 위 글에서 직접 해보면서 정리했지만 세 번째 방법만 해보지 않아 LRUCache를 사용하여 메모리 누수가 발생하지 않도록 관리해보자.
Map을 사용하여 캐시를 만든 경우
public class Main {
public static void main(String[] args) {
PostRepository postRepository = new PostRepository();
int count = 0;
while (true) {
if (System.currentTimeMillis() % 2 == 0) count++;
if (count % 100 == 0) {
CacheKey key = new CacheKey(count);
postRepository.getPostById(key);
}
}
}
}그냥 HashMap 자료구조를 사용한 경우는 위 블로그 글에서 작성했던 코드를 사용했으며 main() 메서드에서 count가 100의 배수가 될때마다 CacheKey를 생성하여 캐시에 넣도록 작성했다.

그리고 다음과 같은 IntelliJ에서 컴파일해준 .class 파일을 이용해서 GC 로깅과 힙 사이즈는 최대 4096MB까지만 늘어나도록 설정했다. 실행 중에 HashMap에는 계속 쌓이기만 하기 때문에 OutOfMemoryError가 발생한 것을 확인할 수 있다.
GC 로깅 실행 결과


처음에 각종 설정정보가 출력되는데 최대 힙 사이즈가 약 4G로 잘 설정된 것을 확인할 수 있다. 그리고 Full GC가 일어나도 메모리는 줄어들지 않고, Old 영역이 거의 차지한 것을 확인할 수 있다.
VisualVM 실행 결과
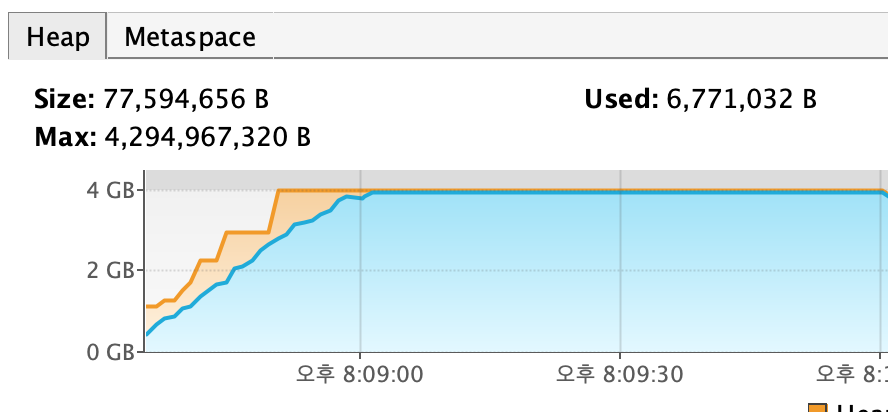
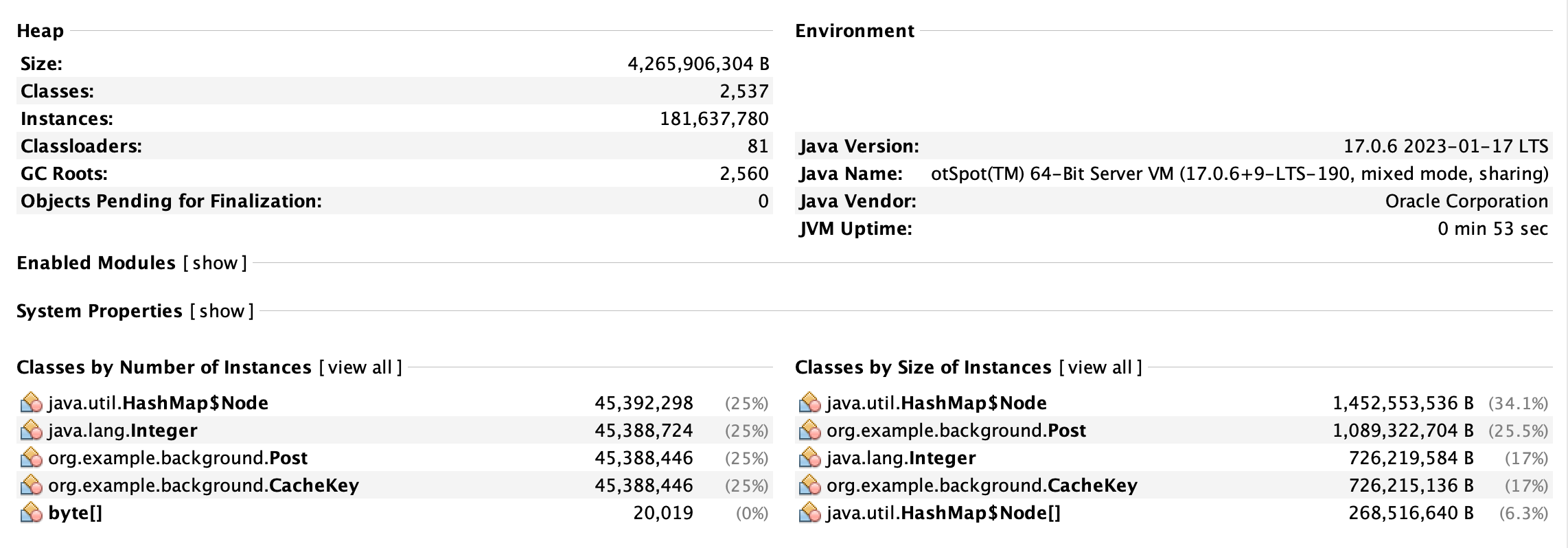
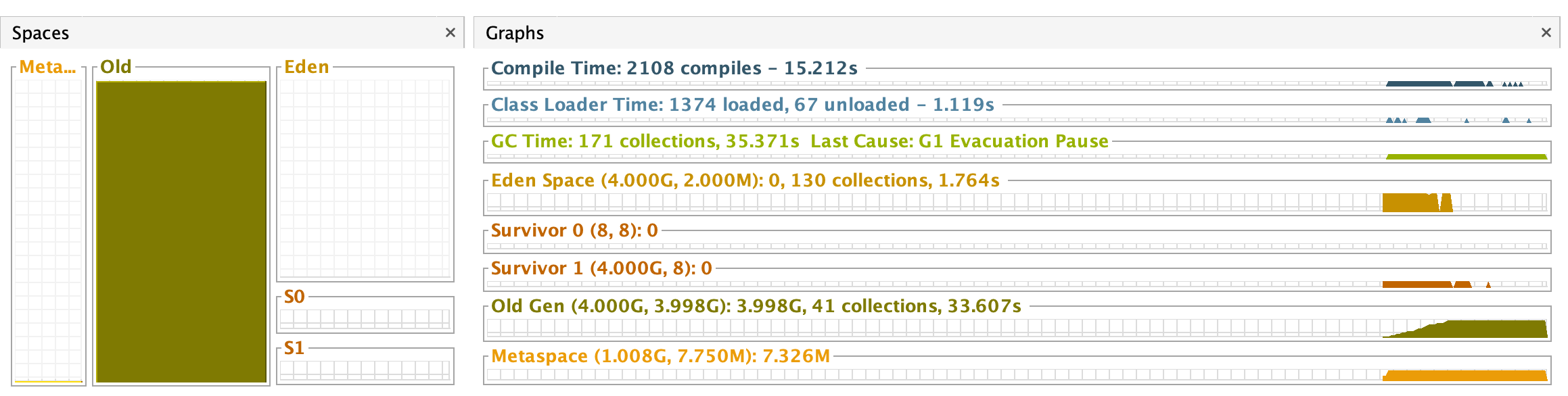
위 GC 로깅에서도 봤듯이 Old 영역이 거의 모두 차지하고 모두 채워진 것을 확인할 수 있다. 결국 비우지 못하고 OutOfMemoryError가 발생한 것이다.
LRUCache를 사용하여 캐시를 만든 경우
public class PostRepository {
private final LRUCache<CacheKey, Post> cache;
public PostRepository(int capacity) {
this.cache = new LRUCache<>(capacity);
}
public Optional<Post> getPostById(CacheKey key) {
if (cache.containsKey(key)) {
return cache.get(key);
}
Post post = new Post();
cache.put(key, post);
return Optional.of(post);
}
public LRUCache<CacheKey, Post> getCache() {
return cache;
}
}
public class Main {
public static void main(String[] args) {
PostRepository postRepository = new PostRepository(100_000);
int count = 0;
while (true) {
if (System.currentTimeMillis() % 2 == 0) count++;
if (count % 100 == 0) {
CacheKey key = new CacheKey((int) (Math.random() * 200_000) + 1);
postRepository.getPostById(key);
}
}
}
}CPUCache 자료구조를 이용하여 캐시를 구현하도록 수정했다. LRUCache의 HashMap이 최대로 가질 수 있는 용량은 100,000개로 설정했다.

해당 명령어를 다시 실행해보자.
GC 로깅 실행 결과
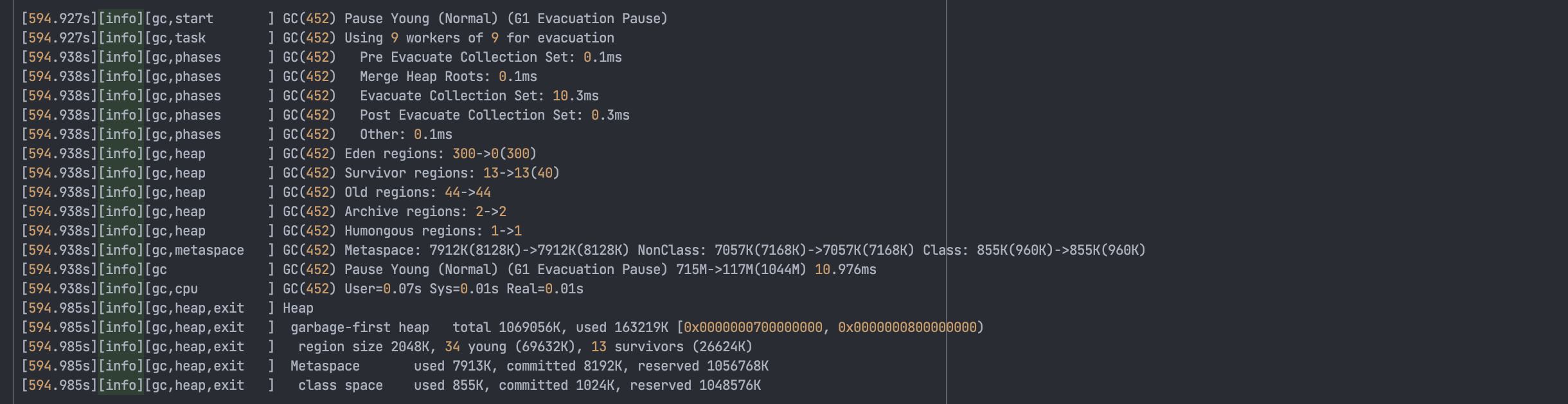
잠시 다른 일하고 온 사이 9분이 넘게 지나있었는데도 불구하고 OutOfMemoryError가 발생하지 않았다. Heap 메모리는 대략 1GB까지만 늘어나있고, 그 이상은 늘어나지 않았다.
VisualVM 실행 결과
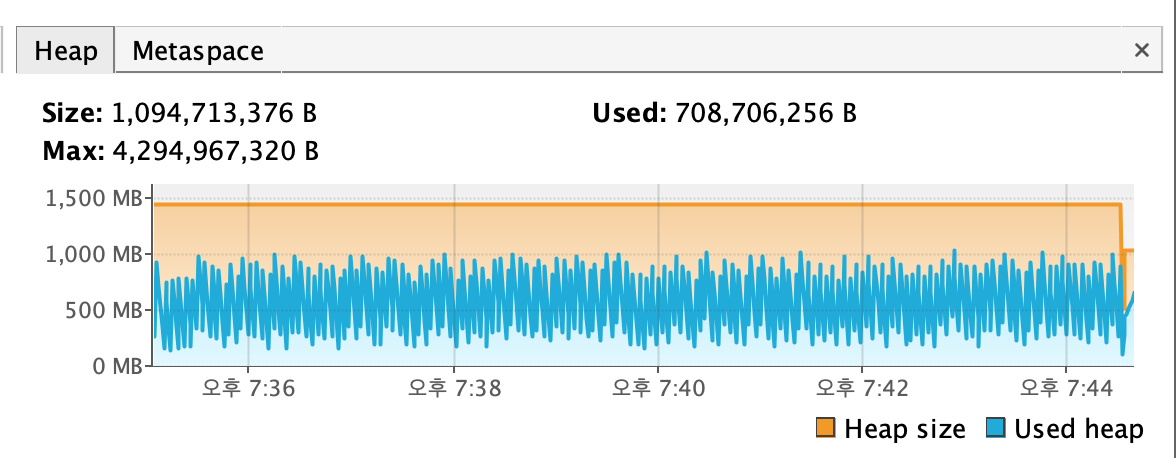
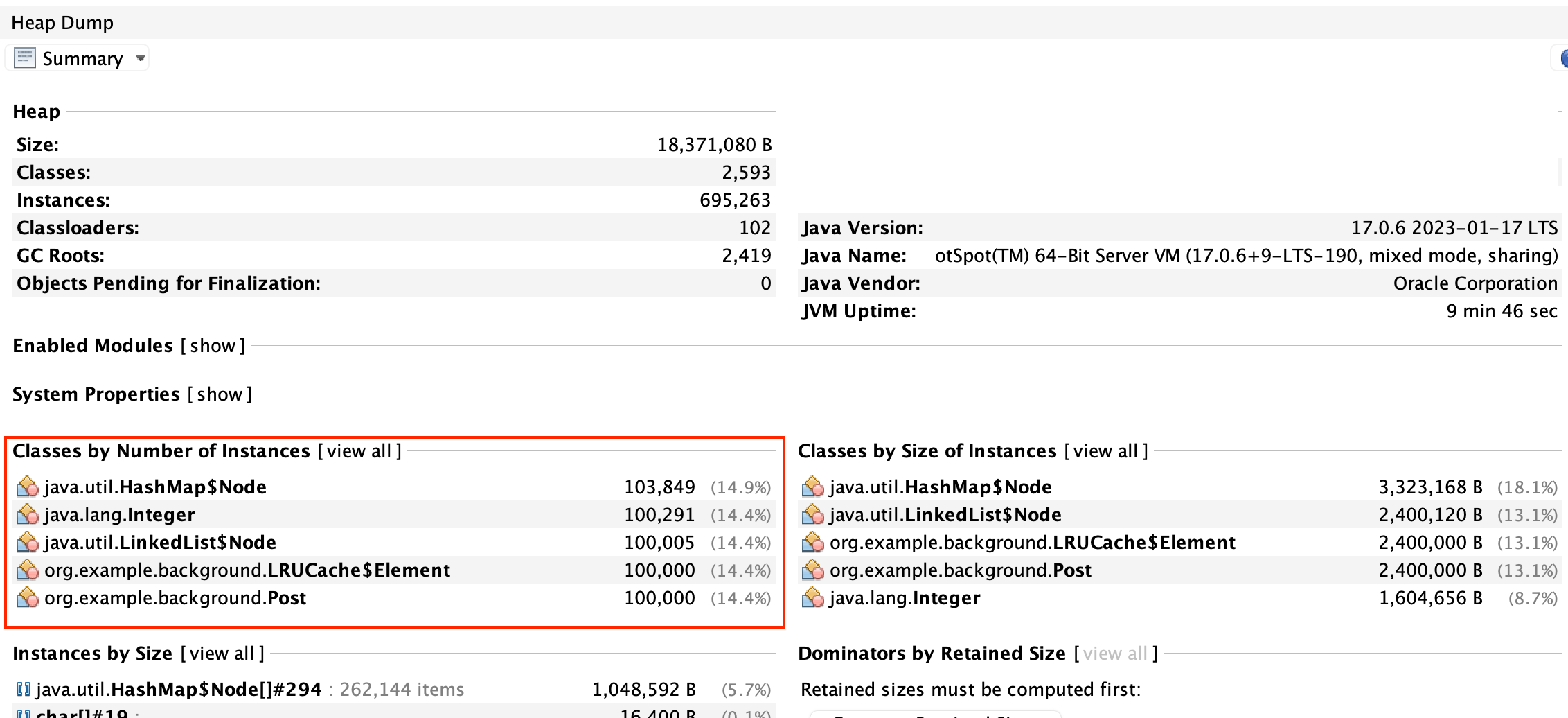

VisualVM을 이용해서 위같은 결과를 얻을 수 있었는데 Heap Max Capacity를 약 4GB로 설정했음에도 약 1GB만을 사용하고 있었고, Post, CacheKey의 개수, 즉 LRUCache의 요소의 수가 100,000개로 제한되어 있는 것을 확인할 수 있다.
이렇게 직접 메모리를 관리하는 LRUCache 알고리즘을 통해 캐시의 용량을 제한하여 메모리 누수를 방지할 수 있었다.
전체 코드는 아래를 보면 확인할 수 있다.
https://github.com/oneny/TIL/tree/main/Java_DataStructure/LRUCache
출처
LRU(Least Recently Used) 알고리즘이란
'Java > Java' 카테고리의 다른 글
| Finalizer와 Cleaner가 아닌 AutoCloseable을 사용하자 (0) | 2023.08.10 |
|---|---|
| JVM 메모리 구조 (0) | 2023.08.09 |
| 메모리 정리하는 방법(null, Weak/SoftReference, Background Thread, 메모리 직접 관리) (0) | 2023.08.06 |
| 표준과 구현 (0) | 2023.07.31 |
| JMH로 warm up 후 테스트하기 (0) | 2023.07.31 |
- Total
- Today
- Yesterday
- 구름톤 챌린지
- 비관적 락
- 넥스트스탭
- Kafka
- nginx
- jvm 메모리 구조
- 카프카
- spring session
- EKS
- transaction
- NeXTSTEP
- Java
- postgresql
- 분산 락
- Redisson
- pessimistic lock
- 구름톤챌린지
- mysql
- 트랜잭션
- Synchronized
- mdcfilter
- nginx configuration
- 낙관적 락
- socket
- sql
- spring webflux
- annotation
- redis session
- 람다
- TDD
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |