
티스토리 뷰
스핀락(spinlock), 뮤텍스(mutex), 세마포(semaphore) (feat. 동기화(synchronization))
oneny 2023. 7. 18. 13:12동기화(Synchronization)
하나의 객체를 두 개의 스레드가 접근하면 어떻게 될까? 왜 동기화가 중요한지에 대해서 살펴보고, 동기화를 하지 않으면 어떤 문제가 발생하는지에 대해서 살펴보자.
상한 귤 세기 예제
public class Counter {
private int state = 0;
public void increment() { state++; }
public int get() { return state; }
}
for (귤 in 귤박스) {
if (귤 상태 is 불량) {
badCounter.increment();
}
}귤박스가 2개 있다고 가정하고 T1, T2 스레드를 사용하여 한 스레드당 하나씩 담당하게 만들었다. CPU가 싱글 코어일 때 T1, T2 스레드는 멀티태스킹 방식(다수의 작업이 CPU와 같은 공용자원을 나누어 사용하는 방식)으로 동작할 것이고, 중간 중간에 컨텍스트 스위칭이 일어나면서 귤 상태가 불량인 귤을 세는 코드를 번갈아가며 CPU에서 실행된다.
T1이 담당한 박스와 T2가 담당한 박스에 각각 상한 귤의 개수가 2개, 5개가 있다고 가정하면 우리가 프로그램이 종료되었을 때 기대하는 badCounter의 state는 7이 될 것이다. 하지만 문제는 항상 이렇게 동작하지 않을 수 있다는 것이다. 왜 그런지에 대해서 자세히 살펴보자.
LOAD state to R1
R1 = R1 + 1
STORE R1 to state
먼저, badCounter 객체의 state가 실제로 CPU 레벨에서 어떻게 동작되는지를 생각해봐야 한다. 우리가 프로그래밍언어 레벨에서 알고 있는 state++;는 CPU가 이해할 수 있는 명령어로 다시 변환되어야 하는데 프로그래밍 언어라는 것은 개발자들이 사람이 이해하기 편한 언어이지 CPU가 바로 이해할 수 있는 언어는 아니기 때문이다. 그래서 개발자가 프로그래밍 언어로 코드를 작성한 state++;는 실제로는 위처럼 3개의 명령어대로 구성되어 CPU에서 실행된다.
위 명령어를 살펴보면 메모리의 state 변수에 있는 값을 R1이라는 CPU 안에 포함된 데이터를 저장하는 레지스터로 로드한 뒤에 레지스터에 있는 값에 1을 더해서 다시 레지스터에 저장을 하고, 최종적으로 레지스터에 있는 값을 다시 메모리의 state 변수에 저장하도록 구성되어 있다.
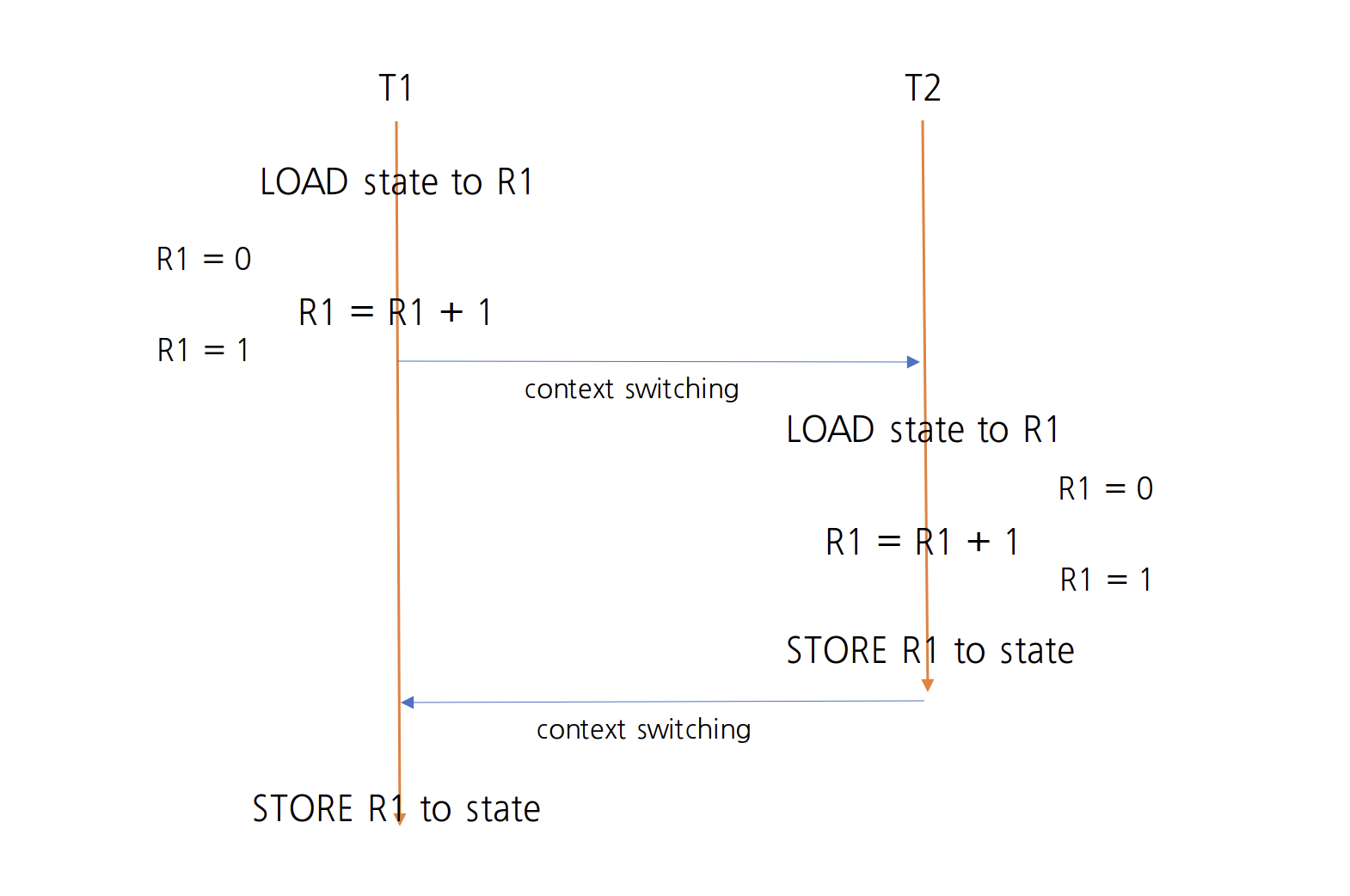
그러면 T1과 T2가 increment를 호출할 때 타이밍에 따라서 어떤 일이 일어날 수 있는지 알아보자.
먼저, T1이 increment라는 메서드를 호출하면 위에서 살펴봤듯이 먼저 LOAD state to R1을 실행하여 메모리 상에 존재하는 state 정보를 CPU에 있는 R1이라는 레지스터에 로드한다. 그러면 이 때의 R1에 있는 값은 0이다. 그 다음 R1 = R1 + 1을 실행하여 1을 더한 후 다시 R1에 저장한다. 근데 문제는 이 타이밍에 컨텍스트 스위칭이 발생했다.
그래서 T2 스레드가 실행된다. T2 스레드 역시 마찬가지로 상한 귤 상태를 보고 incremenet() 메서드를 실행하면 LOAD state to R1이 실행되는데 아직 메모리 상에 존재하는 state 값은 0이기 때문에 R1 레지스터에는 0이 저장된다. 그리고 R1 = R1 + 1이 실행되고, 마지막으로 STORE R1 to state가 실행되어 R1에 저장된 값을 state에 저장한다. 그리고 다시 컨텍스트 스위칭이 발생했다.
T1으로 돌아가면 아까 컨텍스트 스위칭된 시점 이후를 실행해야 하기 때문에 STORE R1 to state가 실행된다. T1 스레드에서 마지막으로 R1 레지스터에 저장된 값을 1이기 때문에 state에는 1이 저장된다.
T1 스레드가 명령어들을 잘 처리하고 있는 와중에 컨텍스트 스위칭이 발생하여 T1이 작업했던 것이 메모리에 써지지 않은 상태에서 T2가 실행되어 버렸기 때문에 우리가 예상과 다른 결과가 나온 것이다.
이러한 상황은 race condition(경쟁 조건)이라 한다. 이는 여러 프로세스/스레드가 동시에 같은 데이터를 조작할 때 타이밍이나 접근 순서에 따라 결과가 달라질 수 있는 상황을 말한다.
그리고 동기화(synchronization)은 여러 프로세스/스레드를 동시에 실행해도 race condition없이 공유 데이터의 일광성을 유지하는 것을 말한다.
어떻게 동기화 시킬 것인가?
위에서 살펴보면 프로그래밍 언어레벨에서의 state++; 명령어가 실제로 CPU에서 실행될 수 있는 명령어 레벨에서 봤을때는 단일 명령어가 아니라 여러 개의 복합 명령어인 것을 확인했다. 그래서 명령어들이 실행되다 중간에서 컨텍스트 스위칭이 발생하면서 문제가 발생했기 때문에 명령어들이 실행되는 동안에는 컨텍스트 스위칭이 일어나지 않도록 해서 문제를 해결할 수도 있다고 생각할 수 있다. 하지만 이 방법은 싱글 코어에서만 가능하고 멀티 코어에서는 불가능한 방법이다. 멀티 코어에서는 두 스레드가 동시에 LOAD state to R1이라는 명령어를 실행해버리면 아까와 같은 상황이 발생할 수도 있기 때문이다.
따라서 increment() 메서드를 실행할 때 한 번에 이 메서드를 한 스레드만 실행할 수 있도록 만들면 어떨까? 다시 말해, 다른 스레드가 이 메서드를 실행하려고 해도 이미 한 스레드에서 실행 중에 있으면 그 스레드가 호출을 끝낼 때까지는 기다리게 하는 것이다. 이런 방식이라면 싱글코어든 멀티코어든 아까와 같은 문제가 발생하지 않을 수 있다. 즉, 멀티코어라 해도 하나의 스레드에서 increment()가 실행중이라면 다른 코어에서 실행 중인 스레드가 increment()를 호출하는 것을 방지할 수 있다.
critical section(임계 영역)
do {
entry section
critical section
exit section
remainder section
} while (true)
이렇게 공유 데이터의 일관성을 보장하기 위해 하나의 프로세스/스레드만 진입해서 실행 가능한 영역을 critical section(임계 영역)이라고 한다. 그리고 하나의 프로세스/스레드만 진입해서 실행하도록 보장하는 것을 mutual exclusion(상호 배제)라 한다.
critical section 문제를 해결하기 위한 뼈대를 위 수도코드와 같다. critical section에 진입하기 전에 entry section에서 진입할 요건이 되는지를 확인한다. 요건을 갖추면 critical section에서 작업을 하고, 작업을 마치면 exit section에서 이후에도 잘 동작할 수 있도록 필요한 조치를 취한다.
critical section problem의 해결책이 되기 위한 조건
- mutual exclusion(상호 배제)
- progress(진행)
- bounded waiting(한정된 대기)
위 세가지 조건을 만족해야 critical section problem의 해결책이 될 수 있다.
첫 번째로는 mutual exclusion(상호 배제)이다.
이 조건은 한 번에 하나의 프로세스/스레드만 critical section에서 실행할 수 있다는 의미이다.
두 번째는 progress(진행)이다.
만약에 critical section이 비어있고 어떤 프로세스/스레드들이 critical section에 들어가길 원한다면 그 중에 하나는 critical section 안에서 실행할 수 있어야 한다는 의미이다. 다시 말해, 진행이 계속될 수 있도록 해야한다는 의미이다.
세 번째 bounded waiting(한정된 대기)이다.
어떤 프로세스/스레드가 critical section에 들어가지 못하고, 무한정 기다리고 있으면 안된다는 조건이다.
Thread-unsafe 조심
SimpleDateFormat
Date formats are not synchronized. It is recommended to create separate format instances for each thread. If multiple threads access a format concurrently, it must be cynchronized externally.
우리가 봤던 Counter 클래스 예제는 멀티스레딩 환경에서 그냥 사용하면 race condition이 존재하기 때문에 Thread-unsafe하다. 이러한 Thread-unsafe 문제는 우리가 개발하는 클래스 뿐만 아니라 프로그래밍 언어 레벨에서 기본적으로 제공하는 클래스에도 이러한 문제가 있을 수 있다. Java에서 지원하는 SimpleDateFormat 클래스를 공식문서에서 보면 위 내용을 확인할 수 있다. 이 클래스를 사용하려면 각각의 독립된 스레드에서 객체를 생성하고, 만약에 여러 스레드에서 이 객체를 공유해서 쓰려고 하면 이것을 쓰는 외부에서 반드시 동기화를 시켜줘야 한다고 나와있다.
따라서 Java에서 지원하는 클래스라고 해서 동시성 문제를 믿고 사용하면 안되고 잘 확인하고 써야한다.
Java8 이상부터 많이 사용하는 LocalDateTime 클래스 같은 경우도 thread-safe해야 한다고 나와있다.

동기화를 위해 자주 사용되는 락 메커니즘
do {
acquire lock
critical section
release lock
remainder section
} while (true)
mutual exclusion을 어떻게 화면 보장할 수 있을까? 이에 대한 해답은 락(Lock)을 사용하는 것이다.
Lock을 사용하는 형태는 위 수도코드처럼 여러 프로세스나 스레드가 Lock을 획득하기 위해 경합을 벌이고, 그 중 성공한 하나의 프로세스/스레드만 critical section에 들어가서 실행한다. 그리고 critical section을 나오면서 갖고 있는 Lock을 반환한다. 이러한 프로세스나 스레드의 동기화에 자주 사용되는 락 메커니즘은 다음과 같다.
- 스핀락(spinlock)
- 뮤텍스(mutex)
- 세마포(semaphore)
Spinlock(스핀락)
volatile int lock = 0; // global
void critical() {
while (testAndSet(&lock) == 1);
... critical section
lock = 0;
}
// 어떤 기능을 하는 것인지 이해돕기용, 아래같은 형태를 가지는 것은 X
int testAndSet(int* lockPtr) {
int oldLock = *lockPtr;
*lockPtr = 1;
return oldLock;
}
T1 스레드: test_and_set(&lock)이 0을 반환하고 lock을 1로 변환 -> critical section에서 작업 -> 끝나면 lock 반환
T2 스레드: lock이 1이기 때문에 while 루프에서 무한 반복하고 있음 -> T1 작업이 끝나 lock = 0; -> while 루프 빠져나와 critical section에서 작업 -> 끝나면 lock 반환(lock = 0;)
위 코드를 살펴보면 여러 스레드들이 동시에 접근하는 글로벌하게 사용되는 lock이 있다. 그리고 여러 스레드들이 호출한 critical()이라는 메서드가 있는데 여러 스레드들이 lock을 얻으려고 경합하고, 락을 획득하는데 성공한 스레드가 critical section으로 들어가 실행한다. 그리고 critical section을 마치면 최종적으로 락을 반환한다.
여기서 testAndSet이라는 함수가 중요한데 공유되는 락에 대해서 무조건 1로 바꿔주는데 반환할 때는 그 락이 원래 가지고 있는 값을 반환한다.
T1과 T2 스레드가 있다고 가정해보자. while 루프 조건문에서 testAndSet 함수를 T1 스레드가 먼저 실행한다고 했을때 lock 값은 0이기 때문에 while 루프를 빠져나오고, testAndSet 안에서 lock 값을 1로 바꾼다. 이후 T2 스레드가 testAndSet을 실행한다고 한들 lock 값은 1이기 때문에 계속 루프를 돌게 된다. 그러다 T1이 critical section에서 작업을 마치고 lock 값을 다시 0으로 바꾸면 T2 스레드는 while 루프 안에서 조건문을 검사하다가 이제는 루프를 빠져나와 critical section에서 작업을 수행한다. 이렇게 락을 가질 수 있을때까지 반복해서 시도하는 방식을 스핀락(spinlock)이라고 한다.
이러한 방식으로 T1과 T2가 동시에 critical section에서 작업을 수행할 수 없도록 할 수 있다. 근데 여기서 의문점이 T1과 T2 스레드가 동시에 TestAndSet을 호출해서 실행하게 되면 둘 다 0을 반환해서 critical section에서 작업을 수행할 수도 있지 않을까 하는 의문이 생길 수 있다.
CPU의 도움
이 testAndSet에는 비밀이 있는데 이것은 CPU의 도움을 받는다는 것이다. 즉, TestAndSet은 CPU에서 지원하는 atomic 명령어로 실행 중간에 간섭받거나 중단되지 않고, 같은 메모리 영역에 대해 동시에 실행되지 않는다는 두 가지 특징이 있다. 즉, testAndSet을 두 개 이상의 프로세스/스레드가 동시에 호출한다고 할지라도 CPU 레벨에서 알아서 먼저 하나를 실행시키고, 그 하나가 실행이 끝나면 이어서 다른 하나를 실행시키는 방식으로 동기화시켜주기 때문에 T1과 T2 스레드가 동시에 testAndSet 함수를 실행시키는 문제를 발생하지 않는다. 만약 멀티코어 환경에서 두 개의 스레드가 testAndSet이라는 명령어를 동시에 실행시켰다 할지라도 뭐가 먼저 실행될지는 알 수 없지만 CPU 레벨에서 알아서 동기적으로 하나를 먼저 실행시키고 그 하나가 끝나면 다른 하나를 실행시켜준다.
spinlock의 단점
하지만 이 스피락 방식은 기다리는 동안 계속 락이 있는지 확인해야 하기 때문에 그 확인하는 과정 자체가 CPU 사이클 잡아먹어 CPU를 낭비한다는 단점이 있다. 이러한 CPU 사이클을 다른 프로세스나 스레드가 유용하기 쓸 수 있는데 확인하는 과정 때문에 낭비가 심해 이를 개선하기 위해서 스레드를 잠시 쉬게 했다가 락이 준비되면 깨울 수 있도록 하는 방식이 등장했다.
Mutex(뮤텍스)
class Mutex {
int value = 1;
int guard = 0;
}
Mutex::lock() {
while (testAndSet(&guard));
if (value == 0) {
... 현재 스레드를 큐에 넣음;
guard = 0; & go to sleep
} else {
value = 0;
guard = 0;
}
}
Mutex::unlock() {
while (testAndSet(&guard));
if (큐에 하나라도 대기중이라면) {
그 중에 하나를 깨운다;
} else {
value = 1;
}
guard = 0;
}
mutex -> lock();
... critical section
mutex -> unlock();
mutex에서는 spinlock과 비슷하지만 여러 프로세스/스레드가 critical section에 들어가기 위해서는 value라는 값을 취득해야만 들어갈 수 있다. 먼저 lock 메서드를 보면 if (value == 0) 조건문을 통해 다른 프로세스/스레드가 lock을 취득한 상태라면 큐에 대기하고, lock을 취득할 수 있다면 value 값을 쥐고 0으로 바꾼다. 마찬가지로 unlock 메서드를 보면 mutex에 lock을 해제할 때 큐에 하나라도 대기중인 것이 있으면 그 중 하나를 깨우고 그게 아니라면 value 값을 1로 바꾼다. 이런 방식으로 value 값을 통해 critical section에서 단 하나의 프로세스/스레드가 실행된다.
guard 역할
그러면 guard는 무엇일까? value라는 값 자체도 여러 프로세스/스레드가 서로 가지려는 공유되는 데이터이기 때문에 value 값을 바꿔줄 때마다 critical section 영역 안에서 안전하게 보호 받으면서 그 값을 바꿔줘야 한다. 그렇지 않으면 여러 프로세스/스레드가 동시에 접근하고 있기 때문에 race condition이 발생할 수도 있다. 그래서 value 값을 critical section 안에서 안전하게 바꿔주는 장치가 guard이다.
먼저 lock 메서드 안에서 value 값을 바꾸는 작업을 하기 전에 guard를 얻기 위해 서로 경합을 하고, while(testAndSet(&guard)); 에서 그 중에 하나가 얻으면 value 값을 바꿔주는 로직을 수행한다. 그 작업이 끝나면 guard 값을 0으로 바꾼다. 마찬가지로 unlock 메서드에서도 value 값을 바꿔주는 로직을 critical section 안에서 보호하기 위해서 그 앞에서 while(testAndSet(&guard));를 먼저 수행하는 것을 확인할 수 있다.
mutex 핵심
mutex에서 핵심이 되는 두 부분이 있다.
먼저, lock을 얻기 위해 경합을 할 때 lock을 자신이 얻을 수 없으면 lock 메서드에서 큐에 들어가서대기하고 있다가 unlock 메서드에서 깨워주는 방식으로 CPU 사이클을 불필요하게 낭비하는 것을 최소화할 수 있다는 점이다.
그리고 위에서 본 testAndSet 함수도 CPU 레벨에서 지원하는 atomic 명령어를 사용하고 있다는 점이다.
mutex가 spinlock보다 항상 좋은걸까?
멀티 코어 환경이고, critical section에서의 작업이 컨텍스트 스위칭보다 더 빨리 끝난다면 스핀락이 뮤텍스보다 더 이점이 있다.
뮤텍스 같은 경우에는 자기가 lock을 가질 수 없으면 일단 잠들어 있다가 나중에 깨워주는 방식인데 이 과정의 컨텍스트 스위칭이 발생하고, 스핀락 같은 경우에는 뮤텍스랑 달리 그냥 내가 lock을 가질 수 있는지 계속 확인하기 때문에 critical section에서의 작업이 더 빨리 끝나는 경우에는 스핀락이 뮤텍스보다 더 이점이 있다.
그러면 왜 멀티 코어 환경이라는 조건이 붙은걸까? 싱글 코어에서는 생각해보면 코어가 하나이기 때문에 내가 스핀락 방식으로 계속 기다리고 있다고 해도 lock을 가지려면 이미 누군가가 가지고 있는 그 lock을 반환해줘야 하는데 결국 컨텍스트 스위칭이 필요하기 때문에 싱글 코어에서는 스핀락이 이점이 전혀 없다.
Semaphore(세마포)
semarphore는 signal mechanism을 가진 하나 이상의 프로세스/스레닥 critical section에 접근 가능하도록 하는 장치이다.
class Semaphore {
int value = 1; // 0, 1, 2, ...
int guard = 0;
}
Semaphore::wait() {
while (test_and_set(&guard));
if (value == 0) {
... 현재 스레드를 큐에 넣음
guard = 0; & go to sleep
} else {
value -= 1;
guard = 0;
}
}
Semaphore::signal() {
while (test_and_set(&guard));
if (큐에 하나라도 대기중이라면) {
그 중에 하나를 깨워서 준비시킨다.
} else {
value += 1;
}
guard = 0;
}
semaphore -> wait();
... critical section
semaphore -> signal();
위 코드를 보면 앞에서 봤던 mutex와 거의 동일하다.
다른 부분만 살펴보면 value라는 값이 처음은 1로 되어있지만 semaphore에서는 1 외의 여러 값들을 가질 수 있다. mutex에서 lock 메서드에서는 value 값을 0으로 바꿔줬다면 semaphore에서는 1씩 감소시키는 것을 확인할 수 있다. 그리고 mutex에서 unlock 메서드는 value를 다시 1로 바꿔줬다면 semaphore에서는 1씩 증가시키는 것을 확인할 수 있다.
왜 이렇게 증가 및 감소시키는 것일까?
semaphore 같은 경우에는 critical section에 프로세스/스레드가 하나 이상 들어갈 수 있도록 하기 위함이다. 물론 semaphore도 하나의 프로세스/스레드만 실행할 수 있도록 value 값을 0으로 초기화하여 mutual exclusion을 보장하게 만들 수 있다. 그러면 하나의 프로세스/스레드가 wait()에서 value 값을 0으로 감소시켜 이후에 wait 메서드를 호출하는 프로세스/스레드는 if (value == 0)에 걸려 큐에 들어가게 된다.
이렇게 value 값으로 1을 가지는 semaphore를 binary semaphore(이진 세마포)라 부르고, 1 보다 큰 value 값으로 가지는 semaphore는 counting semaphore(카운팅 세마포)라 부른다.
semaphore의 순서 제어
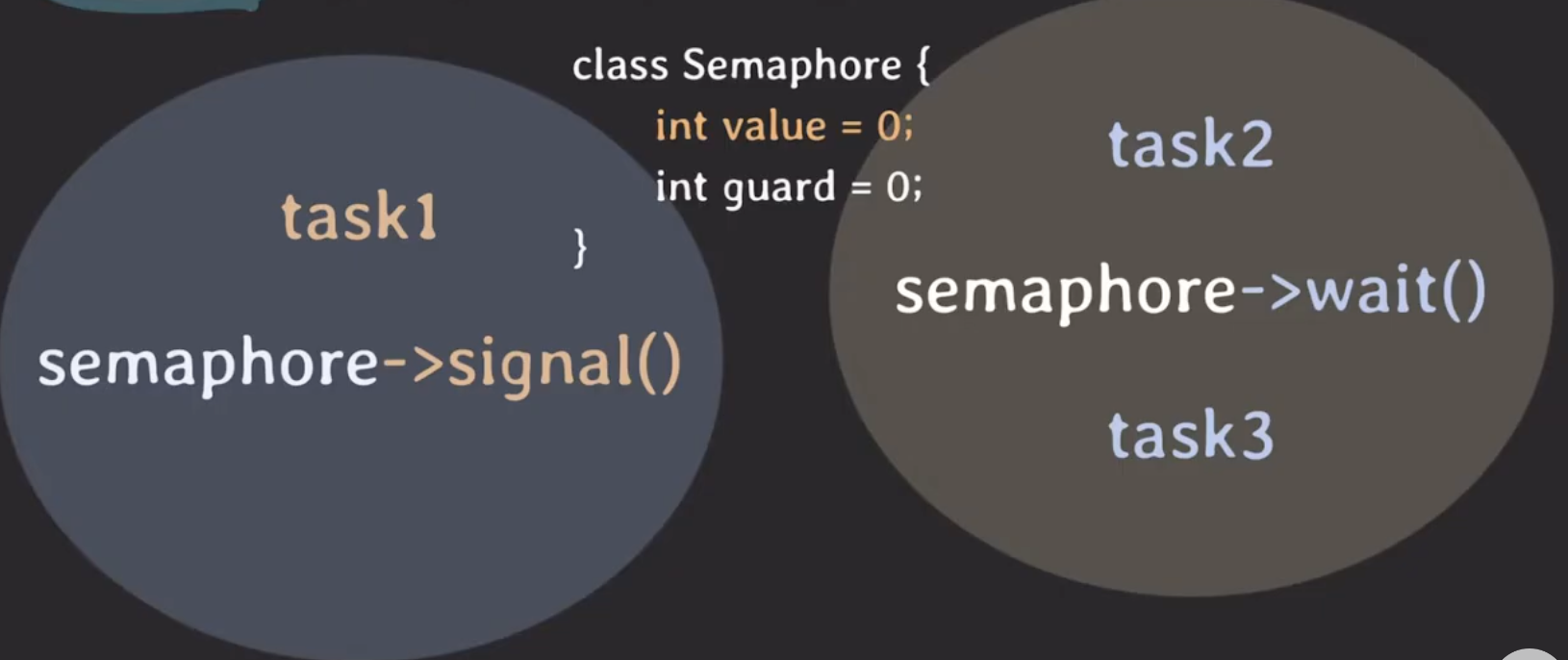
semaphore에는 앞서 말한 순서를 정해주는 signal mechanism이라는 특별한 기능이 있다.
위 그림에는 왼쪽부터 P1, P2 두 개의 프로세스와 semaphore의 value 값이 0으로 되어있고, P1과 P2가 코어를 각각 할당받아서 동시에 시작했다고 가정해보자. P1은 task1이라는 작업을 한 뒤에 signal()을 호출하고, P2는 task2를 수행한 뒤에 그 semaphore에 대해서 wait() 메서드를 호출하고, 이어서 task3를 이어서 작업한다.
P2의 wait()을 먼저 호출할지 P1의 signal()을 먼저 호출할지는 알 수 없지만, task2 먼저 수행되더라도 value 값이 0이기 때문에 task1이 모두 수행되고 난 후 signal()을 호출하여 깨어나 value 값을 1 감소시켜 task3가 시작할 수 있다.
즉, task3를 작업하기 위해서는 반드시 task1의 작업이 끝난 뒤에 수행해야 된다는 것을 의미한다. 이처럼 순서를 정해줄 때에도 semaphore를 사용할 수 있다.
mutex와 binary semaphore는 같은 것 일까?
결론부터 말하자면 다르다. 먼저, mutex는 락을 가진 프로세스/스레드만 락을 해제할 수 있지만 semaphore는 그렇지 않다.
그리고 mutex는 priority inheritance 속성을 가지지만 semaphore는 그 속성이 없다. priority inheritance를 간단히 설명하자면 여러 프로세스나 스레드가 동시에 실행을 하게되면 CPU에서 컨텍스트 스위칭이 발생해서 누구를 먼저 시킬지를 정해야하는데 그것을 스케줄링이라고 한다. 그 스케줄링의 한 가지 방법으로 프로세스나 스레드의 우선순위에 따라서 우선순위가 높은 것을 먼저 실행시키는 방식이다.

위 그림처럼 우선순위가 더 높은 P1과 낮은 P2가 있고, P2가 lock을 쥐어 critical section에서 수행을 하고 있다고 가정해보자.
스케줄링에 의해 P1이 수행을 하다가 lock을 쥐려고 하다보니 lock이 이미 P2가 가지고 있기 때문에 P1은 더 이상 진행을 할 수 없게 된다. 그때부터 P1은 P2에 의존성을 가지게 된다. 그래서 P2가 lock을 반환할 때까지 우선순위가 높아도 아무것도 할 수 없게 된다. 하지만 우선순위에 따른 스케줄링이기 때문에 P2가 우선순위가 많이 낮다면 critical section을 빠져나오는데 오래 걸려 P1은 우선순위가 높아도 아무것도 할 수 없게 된다.
mutex에서는 이 문제를 해결하기 위해 lock을 가진 자만이 lock을 해제할 수 있기 때문에 우선순위가 높은 P1이 P2를 의존하고 있는 상황에서 P2의 우선순위를 P1만큼 올려 스케줄러가 스케줄링을 할 때 우선순위를 P2를 P1만큼 높은 것으로 보고, P2를 먼저 실행시킨다. 그래서 빨리 critical section을 빠져나올 수 있게 된다. 이 때 P2의 우선순위를 P1만큼 올려주는 것을 priority inheritance라 한다.
하지만 semaphore에서는 누가 lock을 해제할지 알 수 없기 때문에 해당 속성이 없다.
따라서 상호 배제만 필요하다면 mutex를, 작업 간의 실행 순서 동기화가 필요하다면 semaphore를 권장한다.
출처
동기화(synchronization), 경쟁 조건(race condition), 임계 영역(critical section)을 자세하게 설명합니다!
스핀락(spinlock), 뮤텍스(mutex), 세마포(semaphore) 각각의 특징과 차이 완벽 설명!
'기타 > CS' 카테고리의 다른 글
| TCP/IP 모델(TCP/IP 4계층) (0) | 2025.07.01 |
|---|---|
| 전자서명 (0) | 2023.09.11 |
| HMAC(Hash-based message authentication code) (0) | 2023.09.09 |
| HTTPS(with 공개키 암호화 방식) (1) | 2023.09.09 |
| blocking I/O vs non-blocking I/O (feat. socket I/O) (0) | 2023.07.17 |
- Total
- Today
- Yesterday
- 카프카
- Kafka
- spring webflux
- Synchronized
- 트랜잭션
- TDD
- transaction
- 구름톤챌린지
- socket
- 람다
- pessimistic lock
- Java
- mdcfilter
- 낙관적 락
- postgresql
- 구름톤 챌린지
- Redisson
- 비관적 락
- spring session
- sql
- 분산 락
- annotation
- nginx configuration
- NeXTSTEP
- nginx
- EKS
- mysql
- 넥스트스탭
- jvm 메모리 구조
- redis session
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |