
티스토리 뷰
몽고DB CRUD

몽고DB는 위 명령행처럼 몽고DB 인스턴스와 상호작용하는 자바스크립트 셸을 제공한다. 셸은 관리 기능이나, 실행 중인 인스턴스를 점검하거나 간단한 기능을 시험하는데 매우 유용하다. 셸은 시작할 때 몽고DB 서버의 test 데이터베이스에 연결하고, 데이터베이스 연결을 전역 변수 db에 할당한다. 따라서 데이터베이스 선택하기 위해서는 use 명령어를 통해 선택할 수 있다. 그리고 셸에서 데이터를 조작하거나 보려면 생성(create), 읽기(read), 갱신(update), 삭제(delete)의 네 가지 기본적인 작업(CRUD)을 할 수 있다.
삽입
삽입은 몽고DB에 데이터를 추가하는 기본 방법이다.
insertOne
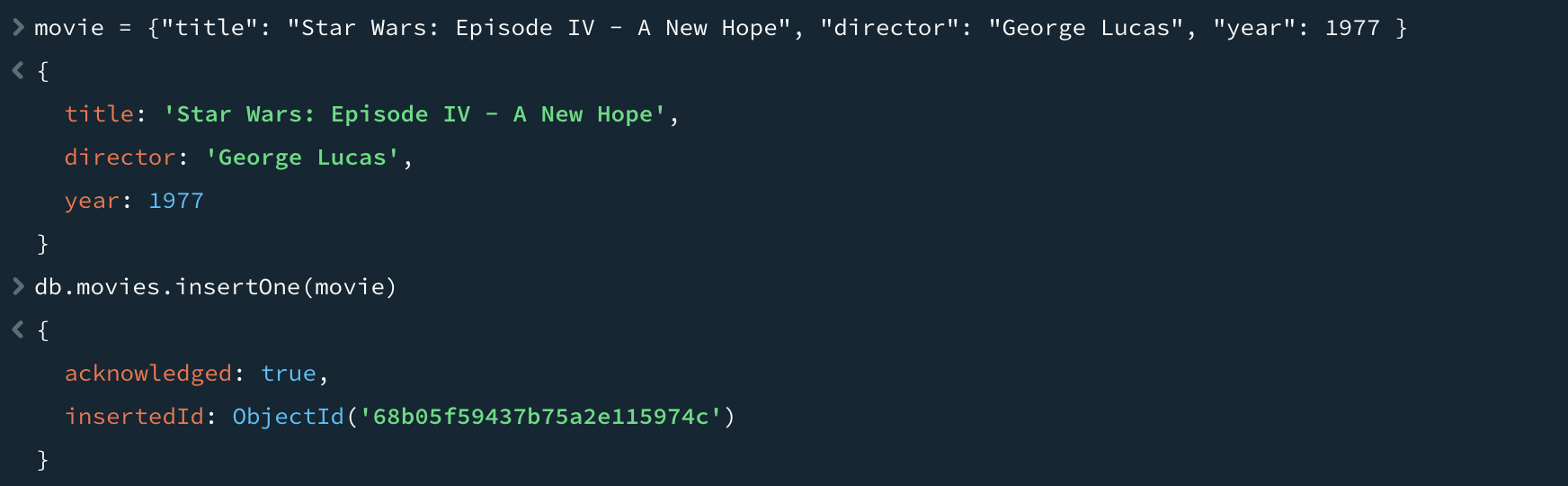
insertOne 함수는 컬렉션에 도큐먼트를 추가한다. 예를 들어, 영화를 저장한다고 가정하자. 우선 도큐먼트를 나타내는 자바스크립트 객체인 movie라는 지역변수(local variable)를 생성한다. movie 변수는 "title", "director", "year"와 같은 키를 가진다. 위 객체는 유효한 몽고DB 도큐먼트이며 insertOne 함수를 이용해 movies 컬렉션에 저장할 수 있다.
insertMany
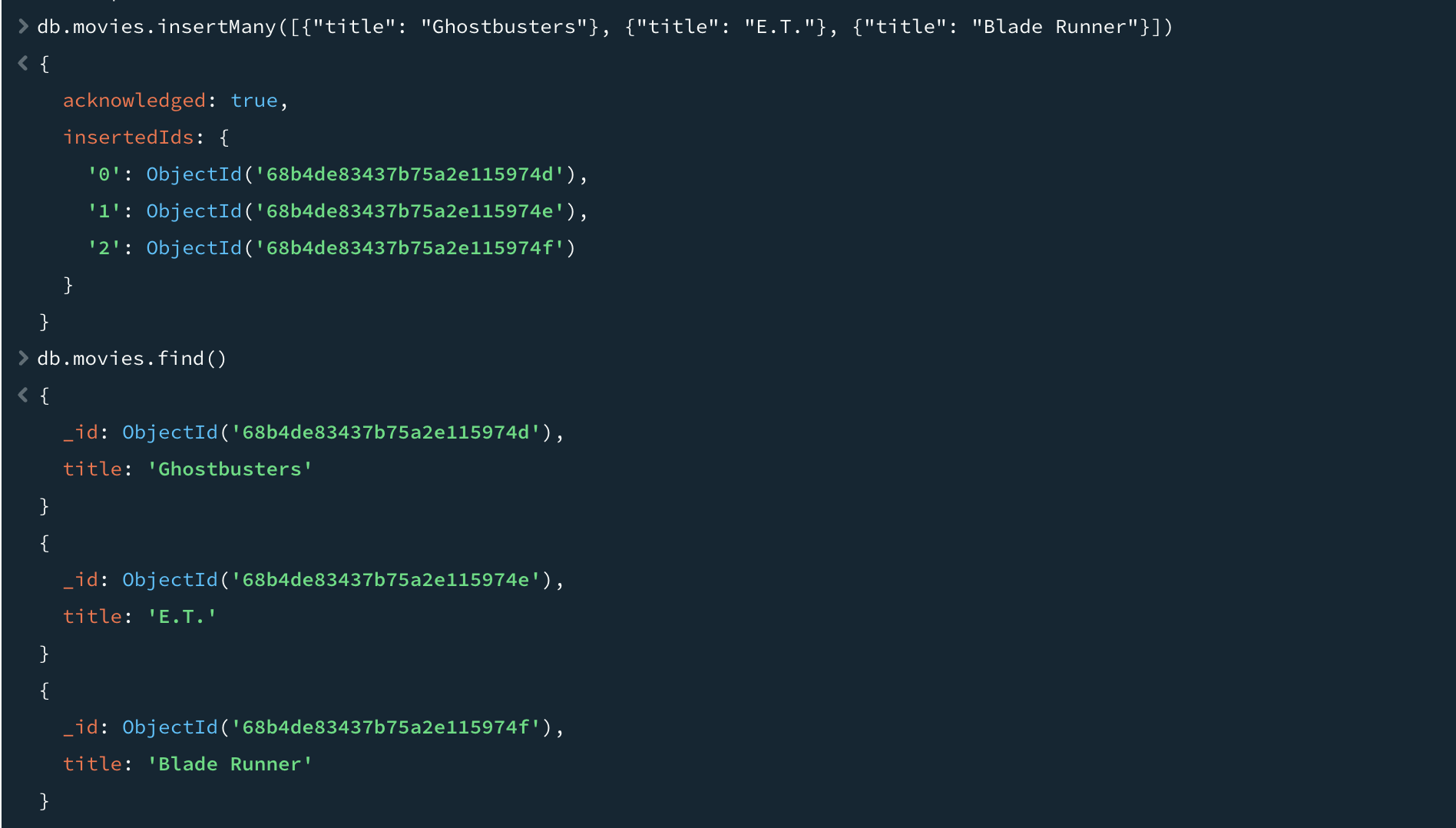
여러 도큐먼트를 컬렉션에 삽입하려면 insertMany로 도큐먼트 배열을 데이터베이스에 전달한다. 코드가 삽입된 각 도큐먼트에 대해 데이터베이스로 왕복하지 않고 도큐먼트를 대량 삽입(bulk insert)하므로 훨씬 더 효율적이고 매우 빨라진다.
몽고DB의 4버전은 48MB보다 큰 메시지를 허용하지 않으므로 한 번에 일괄 삽입할 수 있는 데이터의 크기에는 제한이 있다. 48MB보다 큰 삽입을 시도하면 많은 드라이버는 삽입된 데이터를 48MB 크기의 일괄 삽입 여러 개로 분할한다.
몽고DB는 한 번의 호출로 여러 유형의 작업을 일괄 처리하는 대량 쓰기 API(Bulk Write API)를 지원한다. 확인하고 싶으면 몽고DB 공식문서에서 확인하면 된다.
일괄 삽입 오류
insertMany를 사용해 대량 삽입할 때 배열 중간에 있는 도큐먼트에서 특정 유형의 오류가 발생하는 경우, 정렬 및 비정렬 연산 선택에 따라 발생하는 상황이 달라진다. insertMany 두 번째 매개변수로 옵션 도큐먼트(option document)에 "ordered" 키로 지정할 수 있다.

기본값인 true(정렬된 삽입, ordered insert)를 지정한 경우 도큐먼트가 제공된 순서대로 삽입된다. 정렬된 삽입(ordered intert)의 경우 전달된 배열이 삽입 순서를 정의하여 삽입 도중 오류가 발생하면, 배열에서 해당 지점을 벗언나 도큐먼트는 삽입되지 않는다. 위 예제처럼 정렬된 삽입이 기본값이므로 처음 두 개의 도큐먼트만 삽입된 것을 확인할 수 있다.

false를 지정하면 몽고DB가 성능을 개선하려고 삽입을 재배열할 수 있다. 정렬되지 않은 삽입(unordered insert)의 경우 몽고DB는 일부 삽입이 오류를 발생시키는지 여부에 관계없이 모든 도큐먼트 삽입을 시도한다. 위 예제처럼 정렬되지 않은 삽입을 지정하면 배열의 첫 번째, 두 번째, 네 번째 도큐먼트가 삽입된 것을 확인할 수 있다.
삭제
데이터베이스에 있는 데이터를 삭제하기 위해서는 deleteOne과 deleteMany를 제공한다. 두 메서드 모두 필터 도큐먼트를 첫 번째 매개변수로 사용한다. 예를 들어, 방금 생성한 영화 도큐먼트를 삭제하려고 할 때 필터와 일치하는 모든 도큐먼트를 삭제하려면 deleteMany를 사용하면 된다.
전체 컬렉션을 삭제하려면 db.movies.drop()처럼 drop을 사용하는 편이 더 빠르고 빈 컬렉션에 인덱스를 재생성한다.
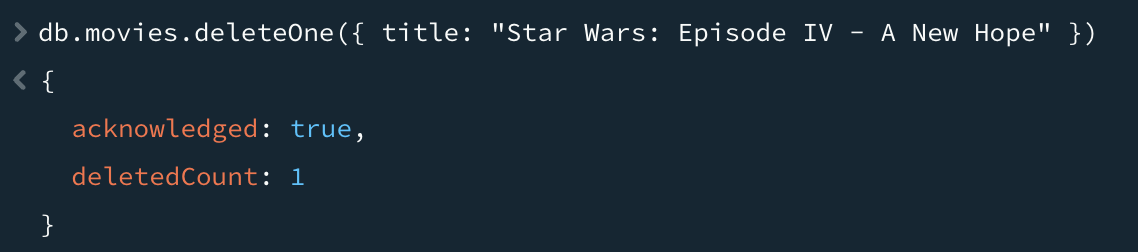
필터는 도큐먼트를 제거할 때 비교할 일련의 기준을 지정한다. deleteOne을 사용하면서 컬렉션 내 여러 도큐먼트와 일치하는 필터를 지정하는 경우에는 필터와 일치하는 첫 번째 도큐먼트를 삭제한다. 어떤 도큐먼트가 먼저 발견되는지는 도큐먼트가 삽입된 순서, 도큐먼트에 어떤 갱신이 이뤄졌는지(일부 스토리지 엔진의 경우), 어떤 인덱스를 지정하는지 등 몇 가지 요인에 따라 달라진다.
갱신
도큐먼트를 데이터베이스에 저장한 후에는 updateOne, updateMany, replaceOne과 같은 갱신 메서드를 사용해 변경할 수 있다.
갱신은 원자적으로 이뤄진다. 갱신 요청 두 개가 동시에 발생하면 서버에 먼저 도착한 요청이 적용된 후 다음 요청이 적용되어 도큐먼트는 변질 없이 안전하게 처리된다. 기본 동작을 원치 않으면 도큐먼트 버저닝 패턴(The Document Versioning Pattern)을 고려할 수 있다.

updateOne과 updateMany는 필터 도큐먼트를 첫 번째 매개변수로, 변경 사항을 설명하는 수정자 도큐먼트를(modifier document)를 두 번째 매개변수로 사용한다. replaceOne도 첫 번째 매개변수로 필터를 사용하지만 두 번째 매개변수는 필터와 일치하는 도큐먼트를 교체할 도큐먼트이다.
위 예제는 도큐먼트에 새 키 값으로 리뷰 배열을 추가한다. 갱신하려면 갱신 연산자(update operator)인 $set을 이용한다. find를 호출해 도큐먼트에서 reviews 키가 생긴 것을 확인할 수 있다.
도큐먼트 치환
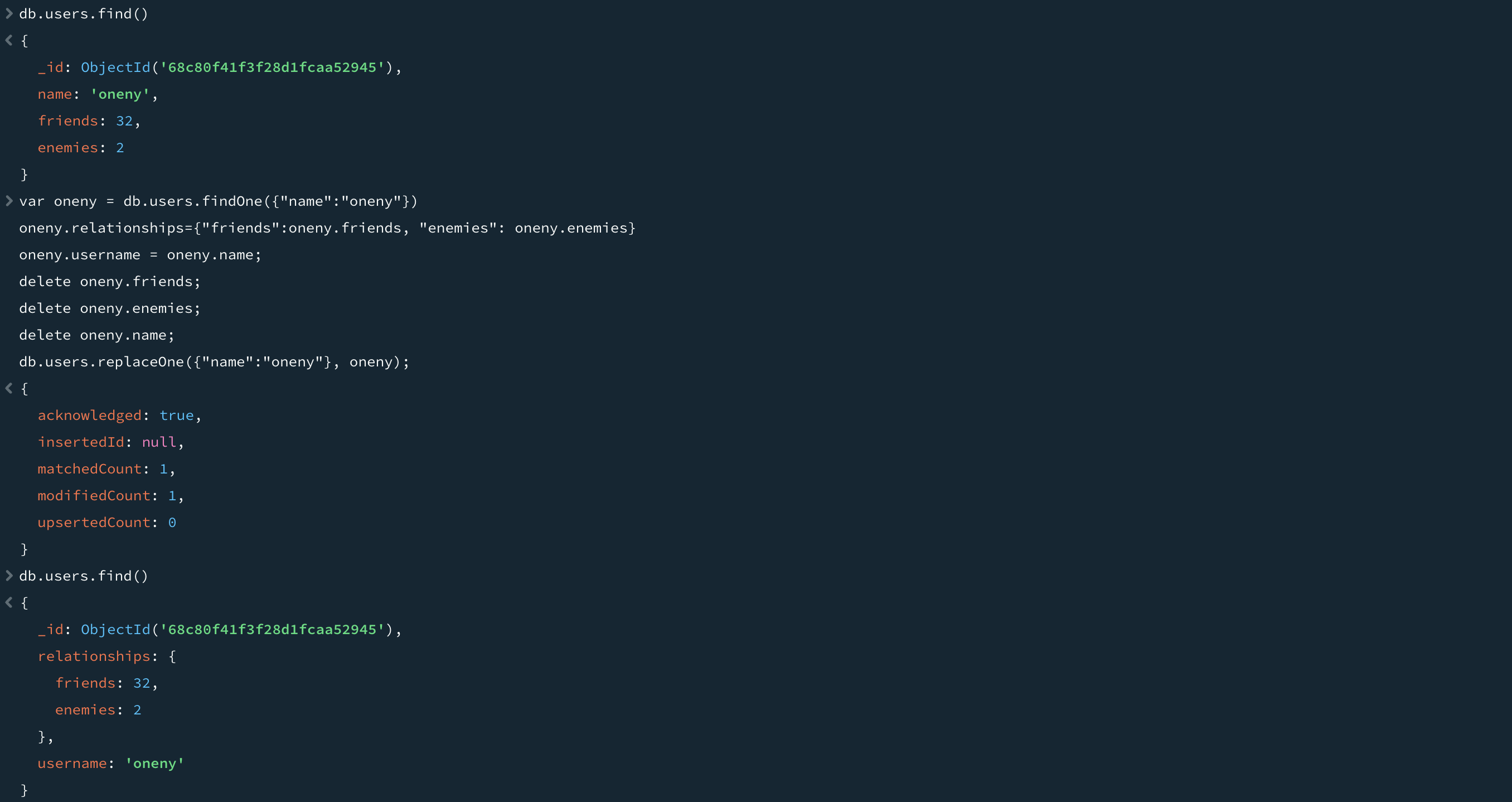
replaceOne은 도큐먼트를 새로운 것으로 완전히 치환한다. 첫 번째 매개변수로 필터를 사용하지만 두 번째 매개변수는 필터와 일치하는 도큐먼트를 교체할 도큐먼이다.
이는 대대적인 스키마 마이그레이션(schema migration)에 유용하다. "friends"와 "enemis" 필드를 relationships라는 서브도큐먼트(subdocument)로 옮겨보자. 셸에서 도큐먼트의 구조를 수정한 후 replaceOne을 사용해 데이터베이스의 버전을 교체할 수 있다.
조건절로 2개 이상의 도큐먼트가 일치하는 경우 중복된 "_id" 값을 갖는 도큐먼트를 생성할 수도 있다. 데이터베이스는 오류를 반환하고 아무것도 변경하지 않는다.
갱신 연산자
도큐먼트의 부분 갱신에는 원자적 갱신 연산자(update operator)를 사용한다. 갱신 연산자는 키를 변경, 추가, 제거하고, 심지어 배열과 내장 도큐먼트를 조작하는 복잡한 갱신 연산을 지정하는 데 사용하는 특수키다.
"$set" 제한자 사용하기
위 예제에서 확인했던 것처럼 "$set"은 필드 값을 설정한다. 필드가 존재하지 않으면 새 필드가 생성된다. 이 기능은 스키마를 갱신하거나 사용자 정의 키(user-defined key)를 추가할 때 편리하다. "$set"은 키의 데이터형도 변경할 수 있고, 반대로 "$unset"으로 키와 값을 모두 제거할 수 있다.
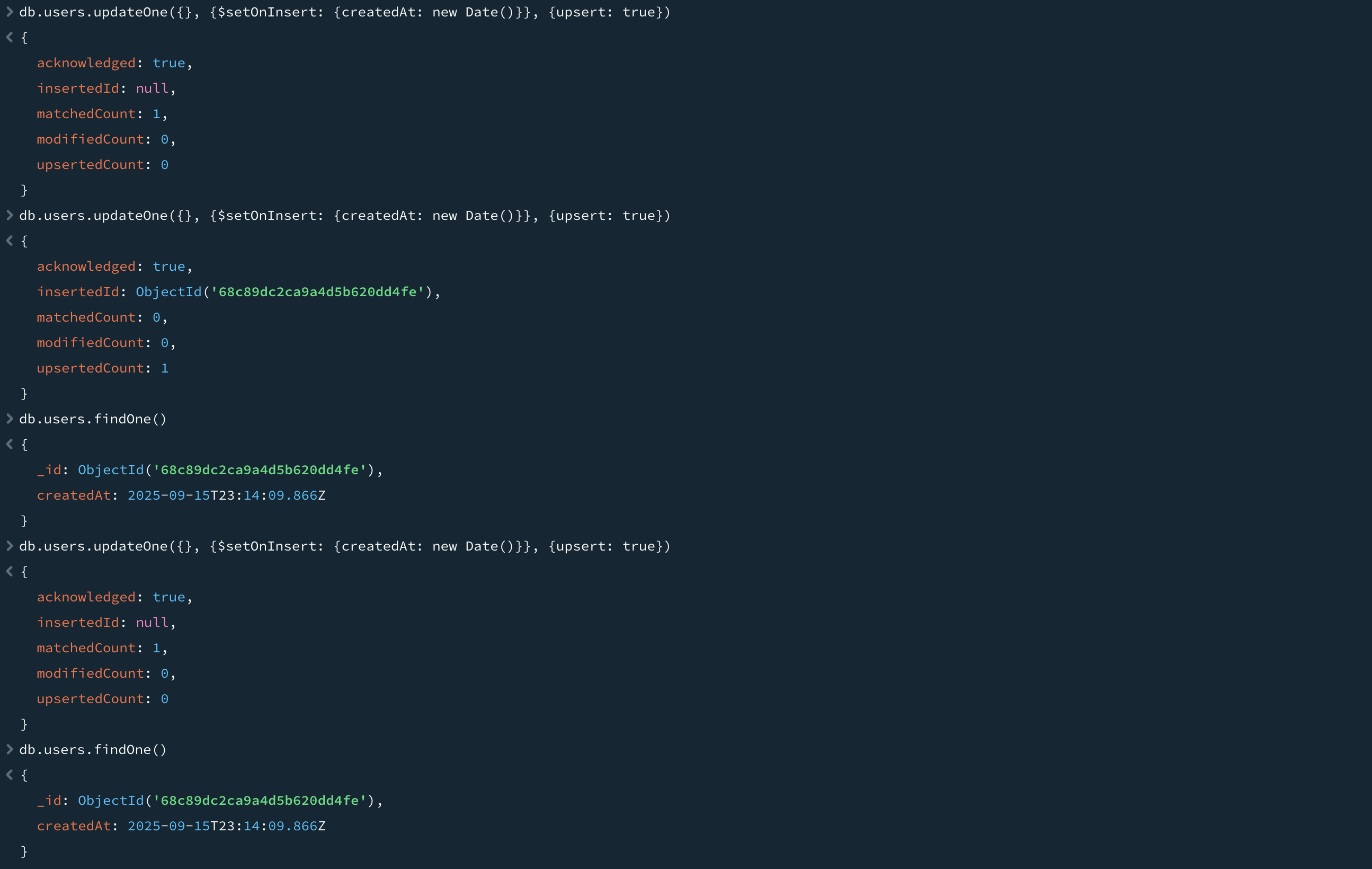
도큐먼트가 생성될 때 필드가 설정되어야 할 때가 종종 있는데, 이후 갱신에서는 변경되지 않아야 한다. 이때 $setOnInsert를 사용한다. $setOnInsert는 도큐먼트가 삽입될 때 필드값을 설정하는 데만 사용하는 연산자다. 위 명령어처럼 다시 갱신하면 기존 도큐먼트를 찾고, 아무것도 입력되지 않으며, createdAt 필드는 변경되지 않는다.
증가와 감소

"$inc" 연산자는 이미 존재하는 키의 값을 변경하거나 새 키를 생성하는 데 사용한다. 분석, 분위기, 투표 등과 같이 자주 변하는 수치 값을 갱신하는 데 매우 유용하다. "$inc"는 int, long, double, decimal 타입 값에만 사용할 수 있다. 숫자가 아닌 값으로 증감을 시도하면 'Modifier "$inc" allowed for numbers only'라는 오류 메시지가 뜬다.
누군가가 페이지를 방문할 때마다 카운터가 증가한다고 가정해보자. 갱신 연산자로 카운터를 원자적으로 증가시킨다. 페이지마다 URL은 "url"키로, 조회수는 "pageviews" 키로 도큐먼트에 저장되어 있다. 누군가가 페이지를 방문할 때마다 URL로 페이지를 찾고 "pageviews" 키의 값을 증가시키려면 "$inc" 제한자(modifier)를 사용한다.
배열 연산자
배열을 다루는 데 갱신 연산자를 사용할 수 있다.
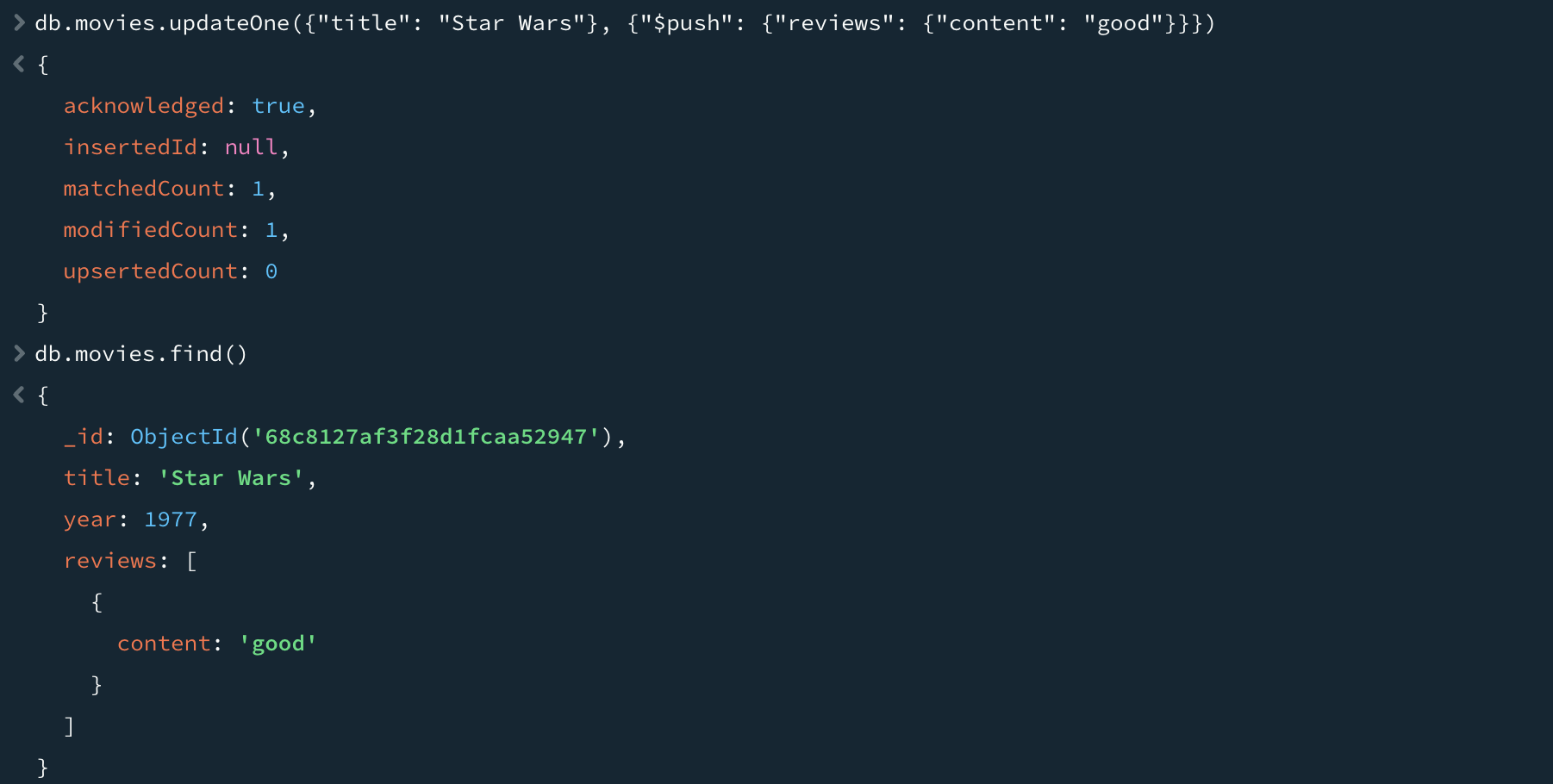
"$push"는 배열이 이미 존재하면 배열 끝에 요소를 추가하고, 존재하지 않으면 새로운 배열을 생성한다. 위 명령어처럼 배열 형태의 "reviews" 키에 삽입하면 리뷰가 추가된 것을 확인할 수 있다.

"$push"에 "$each" 제한자를 사용하면 작업 한 번으로 값을 여러 개 추가할 수 있다.
db.movies.updateOne("genre": "horror",
{"$push": {"top10": {"$each": [{"name": "Nigtmare on Elm Street",
"rating": 6.6],
{"name": "Saw", "rating": 4.3}],
"$slice": 10,
"$sort": {"rating": -1}}}})"$slice"를 "$push"와 결합해 사용하여 배열이 특정 크기 이상으로 늘어나지 않게 효과적으로 'top N' 목록을 만들 수 있다. 위 예제처럼 rating 필드로 배열의 모든 요소를 정렬한 후 처음 10개 요소를 유지하기 위해서 "$sort"도 같이 사용할 수 있다.
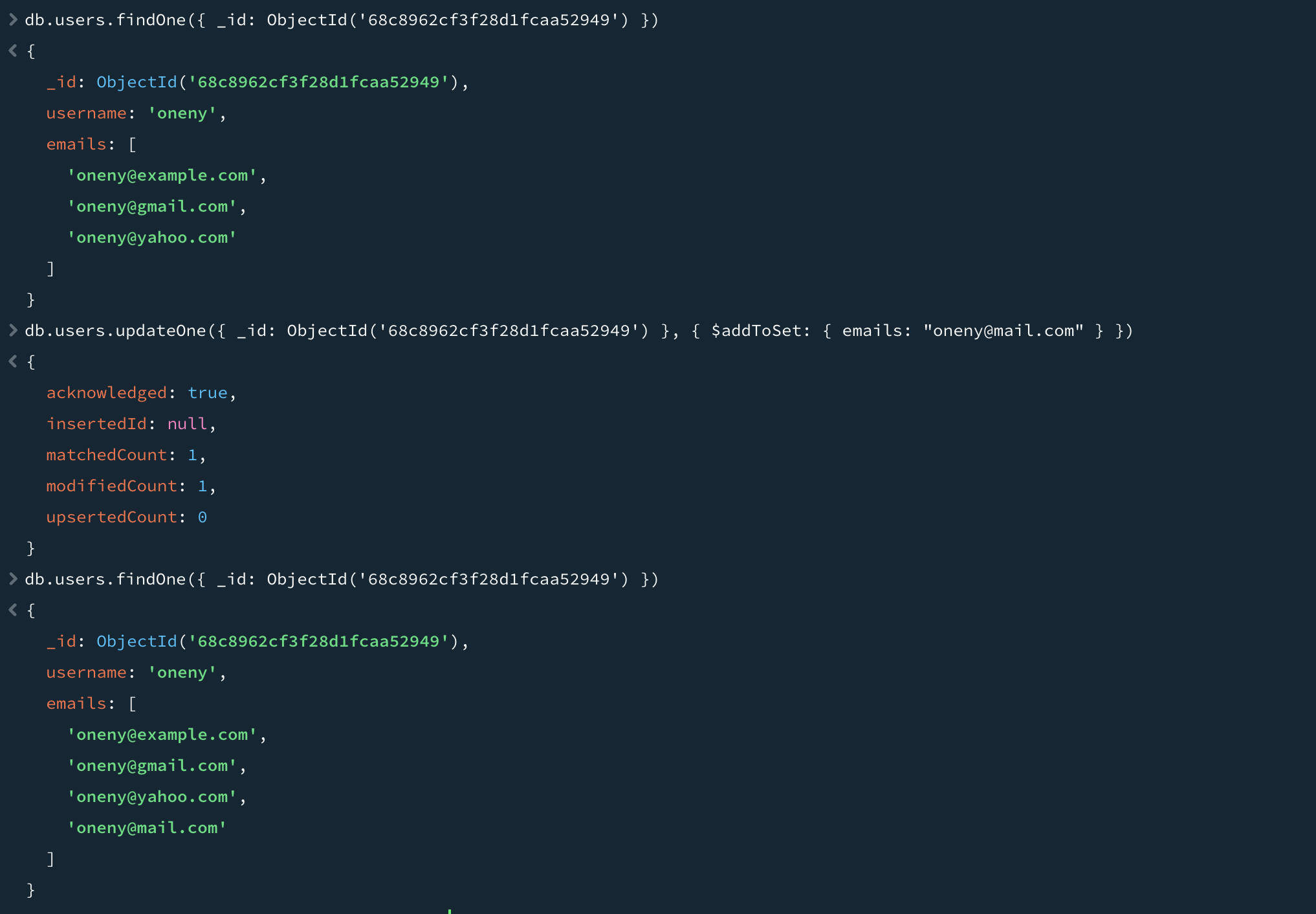
특정 값이 배열에 존재하지 않을 때 해당 값을 추가하면서, 배열을 집합처럼 처리하려면 $addToSet을 사용할 수 있다.
요소 제거하기
배열을 큐나 스택처럼 사용하려면 배열의 양 쪽 끝에서 요소를 제거하는 $pop을 사용한다.
- { $pop: { key: 1 } }: 배열의 마지막부터 요소를 제거
- { $pop: { key: -1 } }: 배열의 처음부터 요소를 제거
주어진 조건에 맞는 배열 요소를 모두 제거할 때는 $pull을 사용한다. 예를 들어, [1, 1, 2, 1]과 같은 배열에서 1을 뽑아내면 배열에는 [2] 하나만 남는다.
갱신 입력(upsert)
db.analytics.updateOne({ url: "/blog" }, { $inc: { pageviews: 1 } }, { upsert: true })갱신 조건에 맞는 도큐먼트가 존재하지 않을 때는 쿼리 도큐먼트와 갱신 도큐먼트를 합쳐서 새로운 도큐먼트를 생성한다. 조건에 맞는 도큐먼트가 발견되면 일반적인 갱신을 수행한다. 갱신 입력을 사용하면 코드를 줄이고 원자적이므로 경쟁 상태를 피할 수 있다. updateOne과 updateMany의 세 번째 매개변수는 옵션 도큐먼트로, 갱신 입력을 지정할 수 있다.
갱신한 도큐먼트 반환

findOneAndDelete, findOneAndReplace, findOneAndUpdate는 updateOne과 달리 사용자가 수정된 도큐먼트의 값을 원자적으로 얻을 수 있다는 점이다. 즉, 경쟁 상태를 만들지 않는다. 기본적으로 도큐먼트의 상태를 수정하기 전에 반환하는데 옵션 도큐먼트의 returnNewDocument 필드를 true로 설정하면 갱신된 도큐먼트를 반환한다.
쿼리
읽기
db.users.find({}, { username: 1, email: 1 })find와 findOne 함수는 컬렉션을 쿼리하는데 사용한다. 쿼리 도큐먼트에 여러 키/값 쌍을 추가해 검색을 제한할 수 있다. 그리고 조회할 도큐먼트 내 키/값 정보가 모두 필요하지 않는 경우에는 두 번째 매개변수에 원하는 키를 지정하면 된다. 이는 네트워크상의 데이터 전송량과 클라이언트 측에서 도큐먼트를 디코딩(decoding)하는 데 드는 시간과 메모리를 줄여준다. username과 email 키 값만 원할 때는 위처럼 쿼리한다.
쿼리 조건
쿼리는 완전 일치(exact match) 외에도 범위, OR절, 부정 조건(negation) 등 더 복잡한 조건으로 검색할 수 있다.
쿼리 조건절
// 18세에서 30세 사이의 사용자 조회
db.users.find({ age: { $gte: 18, $lte: 30 } })
// 2007년 1월 1일 이전에 등록한 사람 조회
start = new Date("01/01/2007")
db.users.find({ registered: { $lt: start } })
// oneny가 아닌 사용자 조회
db.users.find({ username: { $ne: "oneny" } })<, <=, >, >=에 해당하는 비교 연산자는 각각 "$lt", "$lte", "$gt", "$gte"다. 키 값이 특정 값과 일치하지 않는 도큐먼트를 찾는 데는 "not equal"을 나타내는 "$ne"를 사용한다.
OR 쿼리
// 725, 542, 390 번호인 당첨자 조회
db.raffle.find({ ticket_no: { $in: [725, 542, 390] } })
// 당첨 번호를 가지지 않는 사람 조회
db.raffle.find({ ticket_no: { $nin: [725, 542, 390] } })
// 사용자 id에 번호 대신 이름을 쓰도록 점진적으로 이전하고 있다면, 두 조건 중 하나라도 맞는 도큐먼트 조회
db.users.find({ user_id: { $in: [12345, "oneny"] } })
// ticket_no가 세 번호 중 적어도 하나와 일치하거나 winner가 true인 경우 조회
db.raffle.find({ $or: [{ ticket_no: { $nin: [725, 542, 390] } }, { winner: true }] })몽고DB에서 OR 쿼리에는 두 가지 방법이 있다. "$in"은 하나의 키를 다양한 값과 비교하는 쿼리에 사용한다. "$or"은 더 일반적이며, 여러 키를 주어진 값과 비교하는 쿼리에 사용한다.
$in은 매우 유연해 여러 개의 값을 쓸 수 있을 뿐 아니라 서로 다른 데이터형도 쓸 수 있다. 쿼리 옵티마이저는 $in을 더 효율적으로 다루기 때문에 $in을 사용하는 것을 권장한다.
$not
// $mod: 키의 값을 첫 번째 값으로 나눈 후 그 나머지 값의 조건을 두 번째 값으로 기술하는 연산자
// 1, 6, 11, 16 등인 사용자 반환
db.users.find({ id_num: { $mod: [5, 1] } })
// 반대로 2, 3, 4, 5, 7, 8, 9, 10, 12 등인 사용자를 받으려면 $not 사용
db.users.find({ id_num: { $not: { $mod: [5, 1] } } })$not은 메타 조건절(metaconditional)이며 어떤 조건에도 적용할 수 있다. $not은 정규 표현식과 함께 사용해 주어진 패턴과 일치하지 않는 도큐먼트를 찾을 때 특히 유용하다.
형 특정 쿼리
몽고DB에서는 도큐먼트 내에서 다양한 데이터형을 사용할 수 있다. 일부 데이터형은 쿼리 시 형에 특정하게(type-specific) 작동하다.
null
db.c.find({ z: { $eq: null, $exists: true } })
null은 '존재하지 않음'과도 일치한다. 따라서 키가 null인 값을 쿼리하면 해당 키를 갖지 않는 도큐먼트도 반환한다. 값이 null인 키만 찾고 싶으면 키가 null인 값을 쿼리하고, $exists 조건절을 사용해 null 존재 여부를 확인해야 한다.
배열에 쿼리
// apple과 banana 요소를 가진 도큐먼트 쿼리
db.food.find({ fruits: { $all: ["apple", "banana"] } })
// 전체 배열과 정확하게 일치하는 도큐먼트 쿼리
db.food.find({ fruits: ["apple", "banana", "peach"] })
// 배열 내 특정 요소 쿼리(key.index 구문)
db.food.find({ fruit.2: "peach" })2개 이상의 배열 요소가 일치하는 배열을 찾으려면 $all을 사용한다. 이는 배열 내 여러 요소와 일치하는지 확인하게 해주고, 순서는 중요하지 않다. 정확히 배열 요소가 일치하는지 확인하려면 두 번째처럼 쿼리하면 되고, 순서가 다르면 조회되지 않는다.
db.food.find({ fruits: { $size: 3 } })
// 크기 범위 쿼리용으로 도큐먼트에 size 키 추가
db.food.update(criteria, { $push: { fruit: "strawberry" }, $inc: { size: 1 } })
db.food.find({ size: { $gt: 3 } })$size는 특정 크기의 배열을 쿼리하는 유용한 조건절이다. 하지만 $gt 같은 다른 조건절과 결합할 수 없으므로 위처럼 size 키를 추가해 크기의 범위를 쿼리할 수 있다. 하지만 $addToSet 연산자와는 사용할 수 없다.
// 블로그 게시물에서 먼저 달린 댓글 10개 조회
db.blog.posts.findOne(criteria, { comments: { $slice: 10 } })
// 반대로 나중에 달린 댓글 조회
db.blog.posts.findOne(criteria, { comments: { $slice: -10 } })
// 처음 23개를 건너뛰고, 24번째 요소부터 33번째 요소까지 조회
db.blog.posts.findOne(criteria, { comments: { $slice: [23, 10] } })
// 각 도큐먼트에서 Bob이 쓴 댓글 중 첫 번째로 일치하는 댓글 조회
db.blog.posts.find({ comments.name: "bob" }, { comments.$ : 1 })$slice는 배열 요소의 부분집합을 반환받을 수 있다. 또한, 오프셋(offset)광 요소 개수를 지정해 원하는 범위 안에 있는 결과를 반환할 수 있다. 마지막 $ 연산자를 사용하면 특정 기준과 일치하는 요소를 반환받을 수 있다.
{ x: 5 }
{ x: 15 }
{ x: 25 }
{ x: [5, 25] }
// 두 도큐먼트 조회
> db.test.find({ x: { $gt: 10, $lt: 20 } })
{ x: 15 }
{ x: [5, 25] }
// 배열 비교, 비배열 요소는 일치시키지 않음
> db.test.find({ x: { $elemMatch: { $gt: 10, $lt: 20 } } })
> // 결과 없음
// { x: 15 }만 조회
db.test.find({ x: { $gt: 10, $lt: 20 } }).min({ x: 10 }).max({ x: 20 })처음 쿼리는 조회하면 두 개의 도큐먼트가 조회된다. 5와 25 둘 다 10과 20 사이는 아니지만, 25는 첫 번째 절과 일치하고, 5는 두 번째 절과 일치하기 때문에 반환되었다.
$elemMatch 연산자를 사용하면 몽고DB는 두 절을 하나의 배열 요소와 비교한다. 하지만 비배열 요소를 일치시키지 않는다는 함정이 있다. 따라서 $elemMatch는 배열 요소에 대한 범위 쿼리에만 유용하다.
쿼리하는 필드에 인덱스가 있다면 min 함수와 max 함수를 사용해 $gt와 $lt 값 사이로 인덱스 범위를 제한해 쿼리할 수 있다. 그러면 쿼리는 5와 25는 누락시키고 10과 20 사이의 인덱스만 통과시켜 { x: 15 }만 조회된다.
커서(cursor)
# 100개 데이터 입력
for(x=0; x<100;x++) { db.col3.insertOne({"a":x}) }
// 기본 커서 생성
const cursor = db.col3.find()
// 커서 탐색 방법들
cursor.forEach(doc => console.log(doc));
cursor.toArray(); // 모든 결과를 배열로 변환
cursor.hasNext(); // 다음 문서 존재 여부 확인
cursor.next(); // 다음 문서 반환
cursor.limit(10); // 결과 개수 제한
cursor.skip(20); // 처음 20개 건너뛰기
cursor.sort({createdAt: -1}); // 정렬데이터베이스는 커서를 사용해 find의 결과를 반환한다. 일반적으로 클라이언트 측의 커서 구현체는 쿼리의 최종 결과를 강력히 제어하게 해준다.
몽고DB 커서는 쿼리 결과를 효율적으로 탐색하기 위한 포인터 객체로, 대량의 데이터를 메모리에 한 번에 로드하지 않고 순차적으로 접근할 수 있게 해준다. 커서는 배치(batch) 단위로 도큐먼트를 반환하며, 자동으로 서버와 클라이언트 간의 메모리 사용량을 최적화한다. 또한, 결과 개수를 제한하거나, 결과 중 몇 개를 건너뛰거나, 여러 키를 조합한 결과를 어떤 방향으로든 정렬하는 등 다양하게 조작할 수 있다.
서버 측 커서는 메모리와 리소스를 점유한다. 커서가 더는 가져올 결과가 없거나 클라이언트로부터 종료 요청을 받으면 데이터베이스는 점유하고 있던 리소스를 해제한다. 또는, 사용자가 아직 결과를 다 살펴보지 않았고, 커서가 여전히 유효 영역 내에 있더라도 일정 시간(기본 10분) 후 자동으로 만료되어 서버 리소스를 보호한다.
많은 수의 건너뛰기 피하기
// date을 내림차순으로 정렬하고 첫 페이지 조회
const page1 = db.collection
.find({})
.sort({ date: -1 })
.limit(100);
// 다음 페이지 가져오기
const lastDate = page1[page1.length - 1]._id;
const page2 = db.collection
.find({ date: { $lt: lastDate })
.sort({ date: -1 })
.limit(100);도큐먼트 수가 적을 때는 skip을 사용해도 무리가 없지만 skip을 100만건으로 지정하면 100만 건의 도큐먼트를 모두 읽고 버려야 하므로 오프셋이 클수록 성능이 기하급수적으로 저하된다.
위처럼 커서 기반 페이지네이션을 사용하면 100만 개의 도큐먼트 중 마지막 페이지를 조회할 때도 첫 페이지와 동일한 속도로 실행된다. 인덱스를 통해 직접 시작점을 찾아가므로 중간 도큐먼트를 스캔할 필요가 없다.
'DB > MongoDB' 카테고리의 다른 글
| MongoDB 인덱싱 (0) | 2025.10.06 |
|---|---|
| MongoDB (0) | 2025.10.06 |
| MongoDB 트랜잭션 (0) | 2025.10.06 |
- Total
- Today
- Yesterday
- 비관적 락
- spring session
- EKS
- socket
- annotation
- postgresql
- Redisson
- transaction
- 구름톤챌린지
- sql
- 낙관적 락
- pessimistic lock
- NeXTSTEP
- nginx configuration
- jvm 메모리 구조
- 람다
- 분산 락
- nginx
- Kafka
- mdcfilter
- 트랜잭션
- 넥스트스탭
- 구름톤 챌린지
- 카프카
- TDD
- spring webflux
- redis session
- Synchronized
- mysql
- Java
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |