
티스토리 뷰
Prodcuer
애플리케이션이 카프카에 메시지를 써야 하는 상황에는 여러 가지가 있을 수 있다. 감사 혹은 분석을 목적으로 한 사용자 행동 기록, 성능 메트릭 기록, 로그 메시지 저장, 스마트 가전에서의 정보 수집, 다른 애플리케이션과의 비동기적(asynchronous) 통신 수행, 임의의 정보를 데이터베이스에 저장하기 전 버퍼링 등이 있다.
이러한 사용 사례들은 목적이 다양한 만큼 요구 조건 역시 다양하다. 신용카드 트랜잭션 처리하는 경우에는 어떠한 메시지 유실이나 중복도 허용되지 않으면서 지연 시간은 낮고, 처리율은 매우 높아야 한다. 반대로 웹사이트에서 생성되는 클릭 정보를 저장하는 경우에는 조금 유실되거나 중복이 허용될 수 있고, 사용자가 서비스를 이용하는데 문제만 없다면 메시지가 카프카에 도달하는데 몇 초가 걸려도 상관없다. 이처럼 서로 다른 요구 조건은 카프카에 메시지를 쓰기 위해 프로듀서 API를 사용하는 방식과 설정에 영향을 미친다.
카프카 클라이언트인 프로듀서에 대해서 자세히 알아보자.
카프카 프로듀서 생성
public class SimpleProducer {
private static Logger logger = LoggerFactory.getLogger(SimpleProducer.class);
public static void main(String[] args) {
// topic 명
String topicName = "simple-topic";
// KafkaProducer configuration setting
Properties props = new Properties();
// bootstrap.servers, key.serializer.class, value.serializer.class
props.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, KAFKA_CLIENT_URI);
props.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, IntegerSerializer.class.getName());
props.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
try (KafkaProducer<Integer, String> kafkaProducer = new KafkaProducer<>(props)) {
for (int seq = 0; seq < 20; seq++) {
ProducerRecord<Integer, String> record = new ProducerRecord<>(topicName, "hello world");
final int message = seq;
// asynchronous message producing
kafkaProducer.send(record, ((recordMetadata, exception) -> {
if (exception != null) {
logger.info("exception error from broker " + exception.getMessage());
return;
}
logger.info("async message: {}, partition: {}, offset: {}", message, recordMetadata.partition(), recordMetadata.offset());
}));
kafkaProducer.flush(); // 바로 보내는 것이 아닌 batch에 쌓아두기 때문에 flush 호출해서 브로커에 메시지 전송
}
}
}
}카프카에 메시지를 쓰려면 원하는 속성을 지정해서 프로듀서 객체를 생성해야 한다. 카프카 프로듀서는 아래의 3개의 필수 속성값을 갖는다.
- bootstrap.server
- 카프카 클러스터와 첫 연결을 생성하기 위해 프로듀서가 사용할 브로커의 host:port 목록이다.
- 이 값은 모든 브로커를 포함할 필요가 없는데, 프로듀서가 첫 연결을 생성한 뒤 추가 정보를 받아오게 되어 있기 때문이다. 하지만 브로커 중 하나가 작동을 정지하는 경우에도 프로듀서가 클러스터에 연결할 수 있도록 최소 2개 이상을 지정할 것을 권장한다.
- key.serializer
- 카프카에 쓸 레코드의 키의 값을 직렬화하기 위해 Serializer 클래스를 지정해야 한다.
- 카프카 브로커는 메시지의 키값, 밸류값으로 바이트 배열을 받기 때문에 임의의 자바 객체가 전송할 수 있도록 지정해줘야 한다.
- value.serializer
- 카프카에 쓸 레코드의 밸류값을 직렬화하기 위해 Serializer 클래스를 지정해야 한다.
카프카 프로듀서는 언제나 비동기적으로 동작한다. 즉, 메시지를 콜백 함수와 함께 보내면 send() 메서드는 메시지를 버퍼에 저장하고 Future 객체를 반환한다. 그러면 별도의 스레드(Sender)에서 카프카 브로커로 메시지가 보내지고 응답을 받는 시점에서 자동으로 콜백 함수가 호출된다. 하지만 다음 메시지를 전송하기 전 get() 메서드를 호출해서 작업이 완료될 때까지 기다렸다가 실제 성공 여부를 확인하는 동기적인 방식을 사용할 수도 있다.
메시지 Producing 과정
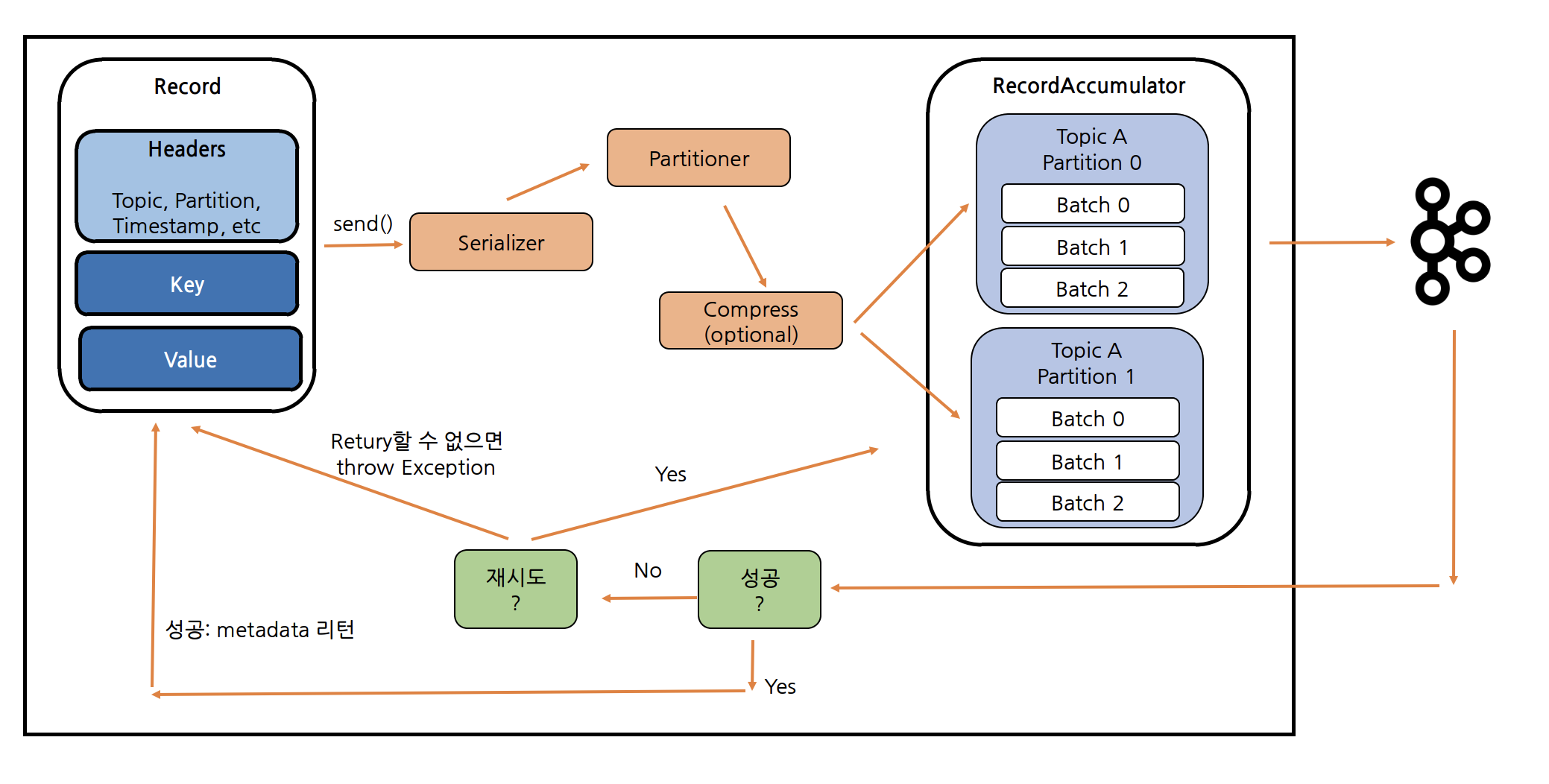
카프카 브로커에 메시지를 보내는 대략적인 과정은 위 그림과 같다. KafkaProducer 객체에서 send() 호출 시 ProducerRecord 넘겨주면 Serializer를 통해 Key와 Value를 바이트 배열로 직렬화하고, Partitioner를 통해 어떤 파티셔너로 갈 지 결정한다. 그러면 버퍼 역할을 하는 RecordAccumulator에서는 토픽의 파티션 별로 max.in.flight.requests.per.connect만큼의 배치를 생성할 수 있고, 해당 배치가 batch.size만큼 차거나 linger.ms 시간만큼 지나면 메시지 브로커에 메시지들을 전송한다.
메시지 보내고 request.timeout.ms동안 응답이 오지 않는다면 retry.backoff.ms(default: 100)마다 대기한 후 retires(default: MAX_INT)만큼 재시도를 진행한다. 그리고 delivery.timeout.ms(배치에 저장된 시점-응답까지의 시간)시간 동안 재시도를 실패하게 된다면 TimeoutException과 함께 콜백을 실행한다.
send() 메서드는 위 과정에서 알 수 있듯이 바로 메시지를 보내 응답을 받는 동기 방식이 아닌 기본적으로 비동기로 동작한다. 따라서 메시지에 대한 결과를 추적할 수 있도록 Future 객체를 반환하기 때문에 get() 메서드를 호출하여 결과르 받을 때까지 대기하거나 RecordMetat와 Exception 인자를 가지는 콜백을 넘겨 별도의 스레드에서 메시지 브로커로부터 응답을 받고 나서의 처리를 진행할 수 있다.
acks = 0
ack가 필요하지 않아 메시지 손실이 다소 있더라도 빠르게 메시지를 보내야 하는 경우에 사용할 수 있다. 이 수준은 자주 사용되지 않는다.
acks = 1
Leader 브로커가 메시지를 수신(commit)하면 ack를 보낸다. Leader 브로커가 Producer에세 ack를 보낸 후, Follower 브로커가 이를 복제하기 전에 Leader 브로커에 장애가 발생하면 Controller가 Follower 브로커 중 하나가 Leader 브로커로 선출하고, Leader였던 브로커가 재기동된다 하더라도 Leadership이 변경된 시점부터 메시지를 삭제(truncate)하기 때문에 메시지가 손실될 수 있다.
따라서 이는 At most once(최대 한 번) 전송을 보장하는 것을 의미한다.
acks = -1, acks = all
위의 acks들은 메시지 손실이 발생할 수 있다. 따라서 모든 Follower 브로커들까지 Commit되면 acks를 보낸다. Commit되기 전에 Leader 브로커에 장애가 발생하면 Controller는 Follwer 브로커 중 하나를 Leader 브로커로 선출하고 Leader 브로커는 커밋은 하지 못했지만 이전 Leader 브로커로부터 복제한 데이터가 있으면 이를 삭제하지 않고, 해당 데이터까지 High Water Mark를 진행한다. 그러면 Producer는 ack를 받지 못했기 때문에 선출된 Leader 브로커에 다시 메시지를 보내기 때문에 enable.idempotence=false인 경우 해당 메시지들에서 중복이 발생할 수 있다.
따라서 이는 At least once(최소 한 번) 전송을 보장하는 것을 의미한다.
enable.idempotence=true
위에서 메시지가 중복으로 저장될 수 있는 상황을 확인했다. 이를 방지하기 위해 나온것이 enable.idempotence 파라미터이다. 해당 파라미터를 true로 설정하면 Producer는 메시지를 보낼 때마다 순차적인 번호(Sequence)와 Producer ID를 헤더에 저장하여 전송한다. 이 Sequence는 메시지의 고유 순차적인 번호로 만약 브로커가 동일한 번호를 가진 메시지를 2개 이상 받을 경우 하나만 저장하여 ack를 응답하고, Producer는 별다른 문제를 발생시키지 않는 DuplicateSequenceException을 받게 된다.
멱등적 프로듀서 기능을 활성화하기 위해서는 max.in.flight.requests.per.connection 파라미터는 5 이하로, retires는 1 이상으로 그리고 acks=all,-1로 설정해야 한다. 만약 이 조건을 만족하지 않는 설정값을 지정한다면 ConfigExcecptiion이 발생한다.
KafkaProducer 생성
partitioner
// Kafka 생성자 내 로직
this.partitioner = (Partitioner)config.getConfiguredInstance("partitioner.class", Partitioner.class, Collections.singletonMap("client.id", this.clientId));
public class DefaultPartitioner implements Partitioner {
private final StickyPartitionCache stickyPartitionCache = new StickyPartitionCache();
public DefaultPartitioner() {
}
public void configure(Map<String, ?> configs) {
}
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
return this.partition(topic, key, keyBytes, value, valueBytes, cluster, cluster.partitionsForTopic(topic).size());
}
// 키 값을 Hashing하여 파티션 별로 균일하게 전송
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster, int numPartitions) {
return keyBytes == null ? this.stickyPartitionCache.partition(topic, cluster) : Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
// ...
}KafkaProducer 객체를 생성하면 partitioner.class 파라미터로 설정된 Parittioner가 결정된다. 커스텀 Partitioner를 지정하지 않는 경우에는 Kafka에서 제공하는 DefaultPartitioner로 메시지를 Kafka의 특정 파티션에 매핑하기 위한 로직을 정의하고 있다.
키가 지정된 상황에서는 키값을 해시한 결과를 기준으로 메시지를 저장할 파티션을 특정한다. 이때 동일한 키값은 항상 동일한 파티션에 저장되는 것이 원칙이기 때문에 파티션을 선택할 때는 토픽의 모든 파티션을 대상으로 선택한다. 즉, 사용 가능한 파티션만 대상으로 하지 않기 때문에 특정한 파티션에 장애가 발생한 상태에서 해당 파티션에 데이터를 쓰려고 할 경우 에러가 발생할 수 있다. 카프카의 복제(replication)과 가용성을 확보한다면 이러한 경우는 상당히 드물다.
public class StickyPartitionCache {
private final ConcurrentMap<String, Integer> indexCache = new ConcurrentHashMap();
public int partition(String topic, Cluster cluster) {
Integer part = (Integer)this.indexCache.get(topic);
return part == null ? this.nextPartition(topic, cluster, -1) : part;
}
public int nextPartition(String topic, Cluster cluster, int prevPartition) {
// ...
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic); // 사용 가능한 파티션 조회
if (availablePartitions.size() < 1) { // 1개 미만인 경우
Integer random = Utils.toPositive(ThreadLocalRandom.current().nextInt());
newPart = random % partitions.size(); // 토픽의 모든 파티션을 대상으로 선택
} else if (availablePartitions.size() == 1) {
newPart = ((PartitionInfo)availablePartitions.get(0)).partition(); // 1개인 경우 해당 파티션 선택
} else {
while(newPart == null || newPart.equals(oldPart)) { // 2개 이상인 경우 사용 가능한 파티션 중 하나 랜덤으로 선택
int random = Utils.toPositive(ThreadLocalRandom.current().nextInt());
newPart = ((PartitionInfo)availablePartitions.get(random % availablePartitions.size())).partition();
}
}
// ...
}
}DefaultPartitioner는 키를 지정하기 않는 경우에 랜덤으로 파티션을 정하고 ConcurrentHashMap 자료구조를 가진 StickyPartitionCache 객체를 사용하여 토픽의 배치가 닫힐 때까지 같은 토픽의 파티션을 고정(stikcy)하는 캐싱 메커니즘으로 되어 있다. 즉, Topic을 기준으로 매번 같은 파티션 번호를 반환하며, 첫 호출 시 Topic 별로 랜덤한 파티션 id를 캐싱하여 해당 값을 고정으로 사용한다. 그리고 위 코드에서 볼 수 있듯이 키를 지정한 경우와 달리 파티션을 결정하는 것이 먼저 사용 가능한 파티션이 있는지 조회한 후 파티션을 결정하는 것을 확인할 수 있다.
keySerializer, valueSerializer
KafkaProducer(ProducerConfig config, Serializer<K> keySerializer, Serializer<V> valueSerializer, ProducerMetadata metadata, KafkaClient kafkaClient, ProducerInterceptors<K, V> interceptors, Time time) {
// ...
if (keySerializer == null) {
this.keySerializer = (Serializer)config.getConfiguredInstance("key.serializer", Serializer.class);
this.keySerializer.configure(config.originals(Collections.singletonMap("client.id", this.clientId)), true);
} else {
config.ignore("key.serializer");
this.keySerializer = keySerializer;
}
if (valueSerializer == null) {
this.valueSerializer = (Serializer)config.getConfiguredInstance("value.serializer", Serializer.class);
this.valueSerializer.configure(config.originals(Collections.singletonMap("client.id", this.clientId)), false);
} else {
config.ignore("value.serializer");
this.valueSerializer = valueSerializer;
}
// ...
}메시지를 바이트 배열로 직렬화하는 KeySerializer와 ValueSerializer를 결정한다. 이 과정에서 오류가 발생할 경우 SerializationException이 발생하게 된다.
RecordAccumulator

KafkaProducer(ProducerConfig config, Serializer<K> keySerializer, Serializer<V> valueSerializer, ProducerMetadata metadata, KafkaClient kafkaClient, ProducerInterceptors<K, V> interceptors, Time time) {
// ...
long retryBackoffMs = config.getLong("retry.backoff.ms");
this.totalMemorySize = config.getLong("buffer.memory");
// delivery.timeout.ms < linger.ms + request.timeout.ms인 경우
// delivery.timeout.ms 값을 linger.ms + request.timeout.ms로 설정
// delivery.timeout.ms는 linger.ms + request.timeout.ms를 아우르는 시간이기 때문
int deliveryTimeoutMs = configureDeliveryTimeout(config, this.log);
this.accumulator = new RecordAccumulator(logContext, config.getInt("batch.size"), this.compressionType, lingerMs(config), retryBackoffMs, deliveryTimeoutMs, this.metrics, "producer-metrics", time, this.apiVersions, this.transactionManager, new BufferPool(this.totalMemorySize, config.getInt("batch.size"), this.metrics, time, "producer-metrics"));
// ...
}
private static int lingerMs(ProducerConfig config) {
return (int)Math.min(config.getLong("linger.ms"), 2147483647L);
}
private static int configureDeliveryTimeout(ProducerConfig config, Logger log) {
int deliveryTimeoutMs = config.getInt("delivery.timeout.ms");
int lingerMs = lingerMs(config);
int requestTimeoutMs = config.getInt("request.timeout.ms");
int lingerAndRequestTimeoutMs = (int)Math.min((long)lingerMs + (long)requestTimeoutMs, 2147483647L);
if (deliveryTimeoutMs < lingerAndRequestTimeoutMs) {
if (config.originals().containsKey("delivery.timeout.ms")) {
throw new ConfigException("delivery.timeout.ms should be equal to or larger than linger.ms + request.timeout.ms");
}
deliveryTimeoutMs = lingerAndRequestTimeoutMs;
log.warn("{} should be equal to or larger than {} + {}. Setting it to {}.", new Object[]{"delivery.timeout.ms", "linger.ms", "request.timeout.ms", lingerAndRequestTimeoutMs});
}
return deliveryTimeoutMs;
}RecordAccumulator는 Partitioner에서 정한 파티션에 보관했다 Sender를 통해 브로커에 메시지를 전송하는 역할을 한다. 메시지를 쓸 때마다 네트워크 상에서 메시지를 전달하는 것은 막대한 오버헤드를 발생시키기 때문에 메시지를 배치 단위로 모아서 쓰면 지연(latency)와 처리량(throughput) 사이에 트레이드오프가 발생할 수 있지만 네트워크 오버헤드는 줄일 수 있다. 따라서 메시지가 전달되는데 걸리는 시간이 조금 늘어나도 더 효율적인 데이터 전송을 위해 배치 단위로 메시지를 전송한다. 배치의 개수는 max.in.flight.requests.per.connection로 결정할 수 있다.
RecordAccumulator 객체를 생성할 때 다음과 같은 파라미터를 전달하는 것을 확인할 수 있다.

- lingers.ms(default: 0, 즉시 보냄)
- 현재 배치를 전송하기 전까지 대기하는 시간
- KafkaProducer는 현재 배치가 가득 차거나 linger.ms에 설정된 제한 시간이 되었을 때 메시지 배치를 전송한다.
- buffer.memory
- 프로듀서가 메시지를 전송하기 전에 메시지를 대기시키는 버퍼의 크기(메모리의 양)
- 만약 애플리케이션이 서버에 전달 가능한 속도보다 더 빠르게 메시지를 전송한다면 버퍼 메모리가 가득찰 수 있다. 이 경우 추가로 호출되는 send()는 max.block.ms 동안 블록되어 버퍼 메모리에 공간이 생기기를 기다리는데 확보되지 않으면 예외를 발생시킨다.
- batch.size(default: 16KB)
- 각각의 배치에 사용될 메모리의 양
- 위에서 설명했듯이 배치가 가득차거나 linger.ms의 제한 시간이 되었을 때 메시지 배치를 전송한다.
- retry.backoff.ms(default: 100)
- 재시도 사이에 추가되는 대기 시간
- 아래 Sender에서 메시지 전송을 포기하고 에러를 발생시키 전까지 재시도를 하는데 각각의 재시도 사이에 대기 시간을 의미한다.
- delivery.timeout.ms(default: 120,000, 2분)
- 전송 준비가 완료된 시점(send()가 문제없이 리턴되고 레코드가 배치에 저장된 시점)에서부터 브로커의 응답을 받거나 전송을 포기하게 되는 시점까지의 제한시간
- 아 값은 linger.ms(배치에서 전송 대기 시간)와 request.timeout.ms(브로커로부터 응답 시간)의 합 보다 커야 하기 때문에 위 코드에서 configureDeliveryTimeout 메서드를 통해서 둘의 합이 크면 delivery.timeout.ms를 둘의 합으로 설정하게 된다.
- Sender Thread에서 retries는 MAX_INT이기 때문에 retry.backoff.ms마다 재시도를 반복하다 delivery.timeout.ms의 제한 시간을 넘어가게 되면 TimeoutException과 함께 콜백을 호출하게 된다.
Sender와 KafkaThread
KafkaProducer(ProducerConfig config, Serializer<K> keySerializer, Serializer<V> valueSerializer, ProducerMetadata metadata, KafkaClient kafkaClient, ProducerInterceptors<K, V> interceptors, Time time) {
// ...
this.clientId = config.getString("client.id");
// ...
this.sender = this.newSender(logContext, kafkaClient, this.metadata);
String ioThreadName = "kafka-producer-network-thread | " + this.clientId;
this.ioThread = new KafkaThread(ioThreadName, this.sender, true);
this.ioThread.start();
// ...
}
Sender newSender(LogContext logContext, KafkaClient kafkaClient, ProducerMetadata metadata) {
int maxInflightRequests = configureInflightRequests(this.producerConfig);
int requestTimeoutMs = this.producerConfig.getInt("request.timeout.ms");
ChannelBuilder channelBuilder = ClientUtils.createChannelBuilder(this.producerConfig, this.time, logContext);
ProducerMetrics metricsRegistry = new ProducerMetrics(this.metrics);
Sensor throttleTimeSensor = Sender.throttleTimeSensor(metricsRegistry.senderMetrics);
KafkaClient client = kafkaClient != null ? kafkaClient : new NetworkClient(new Selector(this.producerConfig.getLong("connections.max.idle.ms"), this.metrics, this.time, "producer", channelBuilder, logContext), metadata, this.clientId, maxInflightRequests, this.producerConfig.getLong("reconnect.backoff.ms"), this.producerConfig.getLong("reconnect.backoff.max.ms"), this.producerConfig.getInt("send.buffer.bytes"), this.producerConfig.getInt("receive.buffer.bytes"), requestTimeoutMs, this.producerConfig.getLong("socket.connection.setup.timeout.ms"), this.producerConfig.getLong("socket.connection.setup.timeout.max.ms"), this.time, true, this.apiVersions, throttleTimeSensor, logContext);
short acks = configureAcks(this.producerConfig, this.log);
return new Sender(logContext, (KafkaClient)client, metadata, this.accumulator, maxInflightRequests == 1, this.producerConfig.getInt("max.request.size"), acks, this.producerConfig.getInt("retries"), metricsRegistry.senderMetrics, this.time, requestTimeoutMs, this.producerConfig.getLong("retry.backoff.ms"), this.transactionManager, this.apiVersions);
}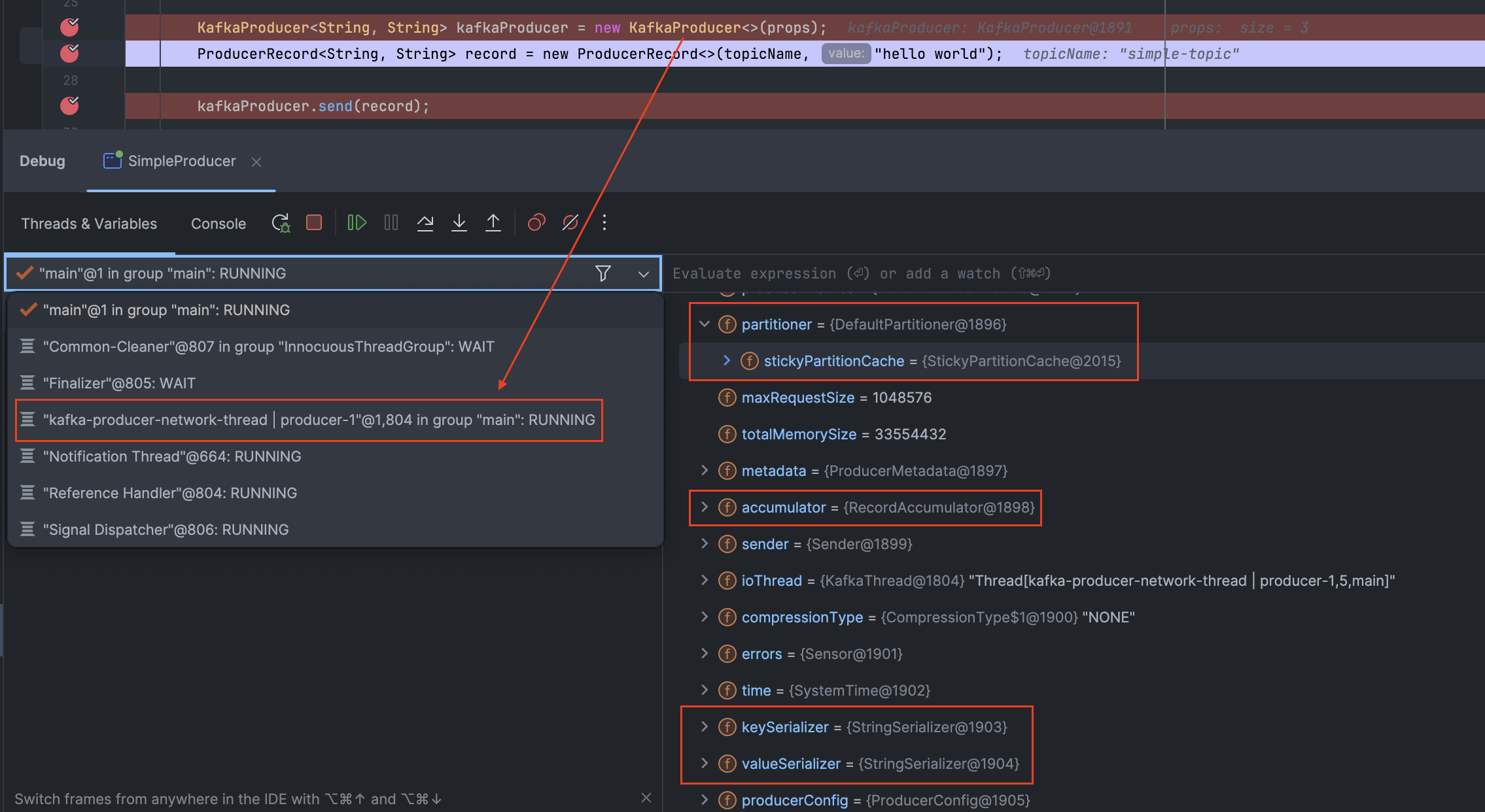
clientId는 프로듀서와 그것을 사용하는 애플리케이션을 구분하기 위한 논리적 식별자이다. Properties 설정 시에 client.id 키를 통해서 임의의 문자열을 사용할 수 있는데 브로커는 프로듀서가 보내온 메시지를 서로 구분하기 위해 이 값을 사용할 수 있다.
실제로 KafkaProeducer 객체를 하나 생성하면 위 사진처럼 KafkaThread에서 네트워크 전송을 담당하는 "kafka-producer-network-thread | producer-1" 이름의 데몬 스레드가 하나 생성된 것을 확인할 수 있다. Kafka 생성자 내 코드를 살펴보면 Runnable을 구현한 Sender 객체를 Thread 상속받은 KafkaThread 객체에 넘겨 실행하는 것을 확인할 수 있다.
- retries(default: MAX_INT)
- 프로듀서가 메시지 전송을 포기하고 에러를 발생시킬 때까지 메시지를 재전송하는 횟수
- request.timeout.ms(default: 30,000, 30초)
- 프로듀서가 데이터를 전송할 때 서버로부터 응답을 받기 위해 얼마나 기다릴 것인지 설정
- 각각의 쓰기 요청 후 전송을 포기하기까지의 대기하는 시간으로 응답 없이 타임아웃이 발생할 경우, 프로듀서는 재전송을 재시도하거나 TimeoutException과 함께 콜백을 호출한다.
send() 메서드 호출 프로세스
public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback) {
ProducerRecord<K, V> interceptedRecord = this.interceptors.onSend(record);
return this.doSend(interceptedRecord, callback);
}
public interface Callback {
void onCompletion(RecordMetadata var1, Exception var2);
}KafkaProducer 객체를 사용하여 send를 호출하면 Future를 반환하는 것을 확인할 수 있다. 즉, KafkaProducer는 비동기 메서드로 전달된 ProducerRecord를 브로커로 즉시 전송되는 동기 방식이 아닌 효율성을 위해 메시지를 배치(batch) 단위로 buffer에 저장한 후 Sender 스레드에서 메시지를 실질적으로 보낸다. 이 때, Future가 완료 상태가 아니면 메인 스레드는 결과를 받기까지 대기한 후 메시지 전송에 대한 결과를 반환받을 수 있다.
Callback은 RecordMetadata 객체와 Exception 객체를 인자로 받는 함수형 인터페이스로 acks 설정에 기반하여 retry가 실행된다.
ProducerMetadata 업데이트
private Future<RecordMetadata> doSend(ProducerRecord<K, V> record, Callback callback) {
ClusterAndWaitTime clusterAndWaitTime;
try {
clusterAndWaitTime = this.waitOnMetadata(record.topic(), record.partition(), nowMs, this.maxBlockTimeMs);
} catch (KafkaException var22) {
if (this.metadata.isClosed()) {
throw new KafkaException("Producer closed while send in progress", var22);
}
throw var22;
}
long remainingWaitMs = Math.max(0L, this.maxBlockTimeMs - clusterAndWaitTime.waitedOnMetadataMs);
}
private ClusterAndWaitTime waitOnMetadata(String topic, Integer partition, long nowMs, long maxWaitMs) throws InterruptedException {
Cluster cluster = this.metadata.fetch(); // cluster 정보 조회
if (cluster.invalidTopics().contains(topic)) {
throw new InvalidTopicException(topic);
} else {
this.metadata.add(topic, nowMs); // ProducerMetadata에서 topics 객체에 추가
Integer partitionsCount = cluster.partitionCountForTopic(topic);
if (partitionsCount != null && (partition == null || partition < partitionsCount)) {
return new ClusterAndWaitTime(cluster, 0L);
} else {
long elapsed = 0L; // 파티션 정보 조회 시간
// Meatadata에서 파티션 정보를 요청해서 가져온 후에 maxWaitMs에서 걸린 시간만큼 빼서 반환
return new ClusterAndWaitTime(cluster, elapsed);
}
}
}

KafkaProducer는 자신이 메시지를 전송할 Topic과 파티션 등의 정보를 관리하기 위해 ProducerMetadata 객체를 가지고 있다. 가장 먼저, 최신 메타데이터를 fetch한 뒤에 topics 객체에 토픽명을 키 값, System.currentTimeMillis()를 값으로 업데이트한다. 그리고 토픽을 보낼 수 있는 파티션의 개수를 확인하는데 해당 정보가 있다면 바로 ClusterAndWaitTime 객체를 반환하고, 해당 정보가 업데이트되지 않았다면 해당 정보를 요청해서 업데이트한 뒤에 ProducerMetadata에 topics에 elapsed만큼 추가하여 업데이트하고, ClusterAndWaitTime의 시간은 max.block.ms에 elapsed를 뺀 시간을 반환한다.
만약 elapsed(doSend 메서드에서 remainingWaitMs) 시간 내로 RecordAccumulator에서 버퍼 메모리 공간이 부족하여 필요한 배치에 append하지 못하면(메모리에 allocate하지 못하면) 아래처럼 BufferExhaustedException 예외가 발생한다.
if (waitingTimeElapsed) {
this.metrics.sensor("buffer-exhausted-records").record();
throw new BufferExhaustedException("Failed to allocate " + size + " bytes within the configured max blocking time " + maxTimeToBlockMs + " ms. Total memory: " + this.totalMemory() + " bytes. Available memory: " + this.availableMemory() + " bytes. Poolable size: " + this.poolableSize() + " bytes");
}
Key와 Value 직렬화
byte[] serializedKey;
try {
serializedKey = this.keySerializer.serialize(record.topic(), record.headers(), record.key());
} catch (ClassCastException var21) {
throw new SerializationException("Can't convert key of class " + record.key().getClass().getName() + " to class " + this.producerConfig.getClass("key.serializer").getName() + " specified in key.serializer", var21);
}
byte[] serializedValue;
try {
serializedValue = this.valueSerializer.serialize(record.topic(), record.headers(), record.value());
} catch (ClassCastException var20) {
throw new SerializationException("Can't convert value of class " + record.value().getClass().getName() + " to class " + this.producerConfig.getClass("value.serializer").getName() + " specified in value.serializer", var20);
}
위 코드에서 바로 확인할 수 있듯이 KeySerializer와 ValueSerializer를 통해 메시지의 데이터를 바이트 배열로 직렬화한다. 만약 이 과정에서 오류가 발생할 경우 SerializationException 예외가 발생한다.
partition 결정
int partition = this.partition(record, serializedKey, serializedValue, cluster);
tp = new TopicPartition(record.topic(), partition);
private int partition(ProducerRecord<K, V> record, byte[] serializedKey, byte[] serializedValue, Cluster cluster) {
Integer partition = record.partition();
return partition != null ? partition : this.partitioner.partition(record.topic(), record.key(), serializedKey, record.value(), serializedValue, cluster);
}KafkaRecord에 partition을 직접 지정하거나 직접 지정하지 않는 경우에는 위에서 partitioner.class 파라미터로 지정한 Partitioner에 의해 파티션을 결정하게 된다.
RecordAccumulator에 메시지 저장
// KafkaProducer.doSend()
RecordAccumulator.RecordAppendResult result = this.accumulator.append(tp, timestamp, serializedKey, serializedValue, headers, interceptCallback, remainingWaitMs, true, nowMs);
public final class RecordAccumulator {
// TopicPartition마다 각각의 Deque<ProducerBatch>를 가지고 있음
private final ConcurrentMap<TopicPartition, Deque<ProducerBatch>> batches;
public RecordAppendResult append(TopicPartition tp, long timestamp, byte[] key, byte[] value, Header[] headers, Callback callback, long maxTimeToBlock, boolean abortOnNewBatch, long nowMs) throws InterruptedException {
// ...
try {
Deque<ProducerBatch> dq = this.getOrCreateDeque(tp);
synchronized(dq) {
if (this.closed) {
throw new KafkaException("Producer closed while send in progress");
}
RecordAppendResult appendResult = this.tryAppend(timestamp, key, value, headers, callback, dq, nowMs);
if (appendResult != null) {
RecordAppendResult var17 = appendResult;
return var17;
}
// ...
}
} finally {
// ...
}
}
private RecordAppendResult tryAppend(long timestamp, byte[] key, byte[] value, Header[] headers, Callback callback, Deque<ProducerBatch> deque, long nowMs) {
ProducerBatch last = (ProducerBatch)deque.peekLast();
if (last != null) {
FutureRecordMetadata future = last.tryAppend(timestamp, key, value, headers, callback, nowMs);
if (future != null) {
return new RecordAppendResult(future, deque.size() > 1 || last.isFull(), false, false);
}
last.closeForRecordAppends();
}
return null;
}
}위에서도 설명했듯이 RecordAccumulator는 메시지를 배치 단위로 관리하는 버퍼 역할을 한다. 이때 batches 객체가 TopicPartition별로 메시지 배치(ProducerBatch)를 관리하는 핵심 자료구조로 append 메서드 실행 시 메시지를 특정 배치에 추가하거나 새로운 배치를 생성하여 메시지를 추가한 후 RecordAppendResult 객체를 반환한다.
Sender
public class Sender implements Runnable {
public void run() {
while(this.running) {
try {
this.runOnce();
} catch (Exception var5) {
this.log.error("Uncaught error in kafka producer I/O thread: ", var5);
}
}
}
void runOnce() {
// ...
long pollTimeout = this.sendProducerData(currentTimeMs);
}
private long sendProducerData(long now) {
Cluster cluster = this.metadata.fetch();
RecordAccumulator.ReadyCheckResult result = this.accumulator.ready(cluster, now);
// ...
Map<Integer, List<ProducerBatch>> batches = this.accumulator.drain(cluster, result.readyNodes, this.maxRequestSize, now);
this.addToInflightBatches(batches);
// ...
this.sendProduceRequests(batches, now);
return pollTimeout;
}
}KafkaThread에서 실행되는 Sender 객체는 KafkaProducer 객체의 close() 메서드가 호출되기 전까지 whil(this.running)을 통해 무한 루프를 돌고 있고 runOnce() 메서드를 호출하고 있다. 그리고 runOnce() 메서드는 sendProducerData() 메서드를 호출하는데 RecordAccumulator 객체에서 ready() 메서드를 통해 배치가 꽉차거나 linger.ms 조건 등을 바탕으로 전송 준비 상태를 판단하여 메시지를 전송할 준비가 된 파티션 목록을 조회하고, drain() 메서드를 통해 준비된 배치 중 실제로 전송할 데이터를 추출한다.
그러면 sendProducerRequests() 메서드를 호출하여 메시지 배치들을 전송하게 된다.
출처
간단한 Kafka Producer를 만들고 동작원리를 알아보자
Kafka - Network Client 깊게 파헤치기
'기타 > kafka' 카테고리의 다른 글
| Kafka Consumer (0) | 2024.12.03 |
|---|
- Total
- Today
- Yesterday
- NeXTSTEP
- Redisson
- sql
- Synchronized
- mdcfilter
- pessimistic lock
- 트랜잭션
- postgresql
- spring session
- spring webflux
- socket
- 구름톤 챌린지
- 낙관적 락
- 넥스트스탭
- Java
- 카프카
- transaction
- 구름톤챌린지
- nginx configuration
- jvm 메모리 구조
- 분산 락
- TDD
- mysql
- 비관적 락
- 람다
- annotation
- nginx
- redis session
- EKS
- Kafka
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |