
티스토리 뷰
MySQL Replication
데이터베이스를 사용하고 운영할 때 가장 중요한 두 가지 요소는 확장성(Scalability)과 가용성(Availability)이다. 이 두 가지 요소를 위해 가장 일반적으로 사용되는 기술인 MySQL 복제는 소스 서버의 데이터를 하나 이상의 레플리카 서버로 복제하여 읽기 작업을 분산시켜 성능을 향상시키는 것을 말한다.
원본 데이터를 가진 서버를 소스(Source) 서버, 복제된 데이터를 가지는 서버를 레플리카(Replica) 서버라고 부른다. 소스 서버에서 데이터 및 스키마에 대한 변경이 최초로 발생하며, 레플리카 서버에서는 이러한 변경 내역을 소스 서버로부터 전달받아 자신이 가지고 있는 데이터에 반영함으로써 소스 서버에 저장된 데이터와 동기화시킨다.
복제 장점
복제를 통해 레플리카 서버를 구축하는 데는 아래와 같은 이유가 있다.
- 스케일 아웃(Scale-out): 서비스를 운영하다 보면 사용자가 늘어나고, DB 서버로 유입되는 쿼리들을 분산시켜 갑자기 늘어나는 트래픽을 대응하는데 훨씬 더 유영한 구조를 구축하고 서비스를 안정적으로 운영할 수 있다.
- 데이터 백업 및 장애 대응: DB 서버에서 사용자의 실수로 데이터가 삭제되면 서비스 운영에 치명적인 영향을 줄 수 있다. 따라서 주기적으로 데이터들을 백업하는 것이 필수적인데 이를 소스 서버에서 하는 경우 DBMS에서 실행 중인 쿼리들이 영향을 받을 수 있다. 따라서 레플리카 서버에서 데이터 백업을 실행하여 소스 서버가 문제가 생겼을 때 대비한 대체 서버의 역할을 할 수 있다.
- 데이터의 지리적 분산: 서비스의 응답 속도는 애플리케이션 서버의 처리 속도와 더불러 다른 서버와의 통신 속도에도 영향을 받으므로 가깝게 위치하는 것이 좋다. 따라서 DB 소스 서버의 위치를 이동시키지 못한다면 복제를 사용해 애플리케이션 서버가 위치한 곳에 기존 DB 서버에 대한 레플리카 서버를 새로 구축해 사용함으로써 응답 속도를 개선할 수 있다.
복제 아키텍처
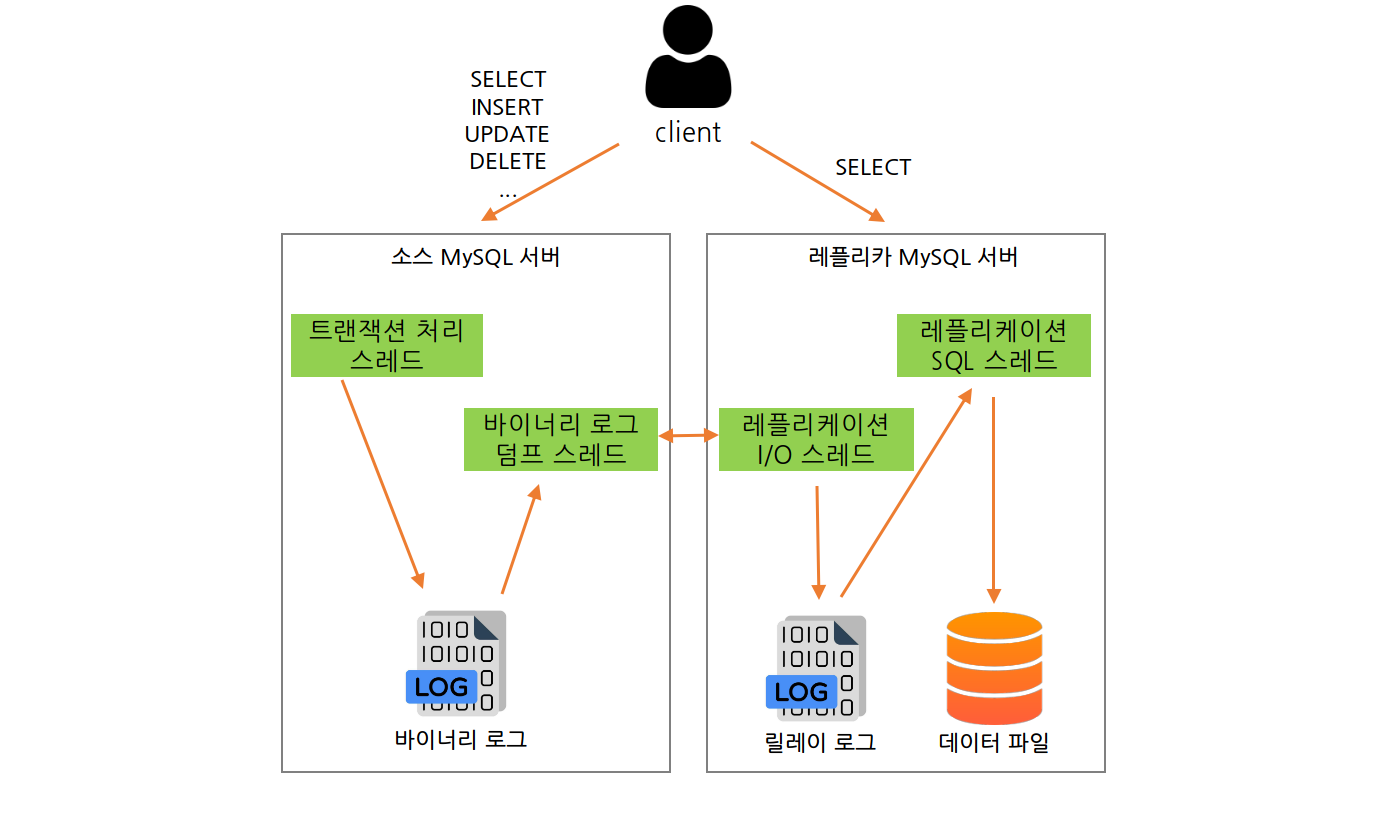
MySQL 서버에서 발생하는 모든 변경 사항은 별도의 로그(Binary Log)라고 한다. 바이너리 로그에는 데이터의 변경 내역뿐만 아니라 데이터베이스나 테이블의 구조 변경과 계정이나 권한의 변경 정보까지 모두 저장된다. MySQL 복제는 이 바이너리 로그를 기반으로 구현됐는데, 소스 서버에서 생성된 바이너리 로그가 레플리카 서버로 전송되고 레플리카 서버에서는 해당 내용을 로컬 디스크에 저장한 뒤 자신이 가진 데이터에 반영함으로써 소스 서버와 레플리카 서버 간에 데이터 동기화가 이루어진다. 레플리카 서버에서 소스 서버의 바이너리 로그를 읽어 들여 따로 로컬 디스크에 저장해둔 파일을 릴레이 로그(Relay Log)라고 한다. MySQL의 복제는 세 개의 스레드에 의해 작동하는데, 이 세 스레드 중 하나는 소스 서버에서, 나머지 두 개의 스레드는 레플리카 서버에 존재한다. 각 스레드의 역할은 다음과 같다.
- 바이너리 로그 덤프 스레드(Binary Log Dump Thread): 레플리카 서버는 데이터 동기화릉 위해 소스 서버에 접속해 바이너리 로그 정보를 요청하는데 소스 서버에서는 레플리카 서버가 연결될 때 내부적으로 바이너리 로그 덤프 스레드를 생성해서 바이너리 로그의 내용을 레플리카 서버로 전송한다.
- 레플리케이션 I/O 스레드(Replication I/O Thread): I/O 스레드는 소스 서버의 바이너리 로그 덤프 스레드로부터 바이너리 로그 이벤트를 가져와 로컬 서버의 파일(릴레이 로그)로 저장하는 역할을 담당한다. 소스 서버의 바이너리 로그를 읽어서 파일로 쓰는 역할만 한다.
- 레플리케이션 SQL 스레드(Replication SQL Thread): SQL 스레드는 I/O 스레드에 의해 작성된 릴레이 로그 파일의 이벤트들을 읽고 실행한다.
바이너리 로그 파일 위치 기반 복제
바이너리 로그 파일 위치 기반 복제는 MySQL에 복제 기능이 처음 도입됐을 때부터 제공된 방식으로, 레플리카 서버에서 소스 서버의 바이너리 로그 파일명과 파일 내에서의 위치(Offset 또는 Position)로 개별 바이너리 로그 이벤트를 식별해서 복제가 진행되는 형태를 말한다.
바이너리 로그 파일 위치 기반에 중요한 부분 중 하나로 복제에 참여한 MySQL 서버들이 모두 고유한 server_id 값을 가지고 있어야 한다는 점이 있다. 바이너리 로그에는 각 이벤트별로 이 이벤트가 최초로 발생한 MySQL 서버를 식별하기 위해 부가적인 정보도 함께 저장되는데, 바로 MySQL 서버의 server_id 값이다.
바이너리 로그 파일 위치 기반 복제에서는 바이너리 로그 파일에 기록된 이벤트가 레플리카 서버에 설정된 server_id 값과 동일한 server_id 값을 가지는 경우 자신의 서버에서 발생한 이벤트로 간주해서 레플리카 서버에서는 해당 이벤트를 적용하지 않고 무시하게 된다. 그래서 바이너리 로그 파일 위치 기반 복제를 구축할 때는 복제의 구성원이 되는 모든 MySQL 서버가 고유한 server_id 값을 갖도록 설정해야 한다.
소스 서버(Source Server) 설정
server-id = 1
log_bin = /var/log/mysql/mysql-bin.log
max_binlog_size = 100M
binlog_do_db = (생성한 database명)
expire_logs_days=10
MySQL의 설정 파일(my.cnf)은 여러 곳에 위치할 수 있지만 mysql --help 명령어를 통해서 우선순위를 확인할 수 있다. 그리고 소스 서버의 my.cnf에서 복제와 관련된 설정은 위와 같고 필요한 설정을 사용하면 된다.
- server_id: 서버의 고유 식별자
- log_bin: 바이너리 로그 파일의 경로 지정
- max_binlog_size: 각 바이너리 로그 파일의 최대 크기 지정. 이 크기를 초과하면 새로운 바이너리 로그 파일 생성된다. 큰 파일 크기는 로그 파일을 더 자주 교체하게 하므로 주기적인 백업 및 로그 관리에 유용하다.
- binlog_do_db: 특정 데이터베이스에 대한 바이너리 로깅을 활성화할 수 있다.
- expire_logs_days: 로그의 보관 주기(일)을 설정
replication용 계정 생성
CREATE USER '계정'@'IP' IDENTIFIED BY '패스워드';
GRANT REPLICATION SLAVE ON '데이터베이스명'.* TO '계정'@'IP' IDENTIFIED BY '패스워드';레플리카 서버가 소스 서버로부터 바이너리 로그를 가져오려면 소스 서버에 접속해야 하므로 접속 시 사용할 DB 계정이 필요하다. 따라서 복제 시작하기 전 소스 서버에서 미리 준비되어 있어야 하며, 이 계정은 반드시 "REPLICATION SLAVE" 권한을 가지고 있어야 한다.
데이터 복사
mysqldump -u root -p (데이터베이스명) > replica.sql
scp replica.sql root@115.85.181.75:/root/
이제 소스 서버의 데이터를 레플리카 서버로 가져와서 적재해야 하는데, 일반적으로 데이터가 크지 않다면 mysqldump 등과 같은 툴을 이용해 소스 서버에서 데이터를 내려받아 레플리카 서버로 복사하면 된다. 그리고 scp 명령어를 사용하여 파일을 레플리카 서버로 전송해줬다.


dump한 sql 파일을 열어보면 해당 테이블이 있는 경우 삭제한 다음 생성하고 테이블에 쓰기 작업에 대한 락을 건 후 원본 데이터들을 쓰기 작업하는 것을 확인할 수 있다. 그리고 쓰기 작업이 끝나면 테이블 잠금을 푼다.
Master db 정보 확인

위 명령어를 통해 마스터의 상태를 확인할 수 있다 레플리카 서버에 소스 서버 정보를 추가할 때 File 값과 Position 값이 필요하므로 기억해둬야 한다.
레플리카 서버(Replica Server)

mysql -u root -p DB명 < replica.sql레플리카 서버에서는 relay_log의 파일 위치 설정을 추가해줬다. 그리고 소스 서버로부터 받아온 설정 파일을 데이터베이스 생성한 후 적용했다.
레플리카 시작
CHANGE MASTER TO MASTER_HOST='MASTER DB IP', MASTER_PORT=3306, MASTER_USER='계정', MASTER_PASSWORD='패스워드', MASTER_LOG_FILE='mysql-bin.000002', MASTER_LOG_POS=157;
START SLAVE;MySQL에서 소스 서버의 정보(IP, 포트, 유저 이름, 비밀번호, 위에서 살펴본 File과 Position 값)를 추가하여 복제 설정 명령어를 실행한 후 SLAVE를 실행시킨다.
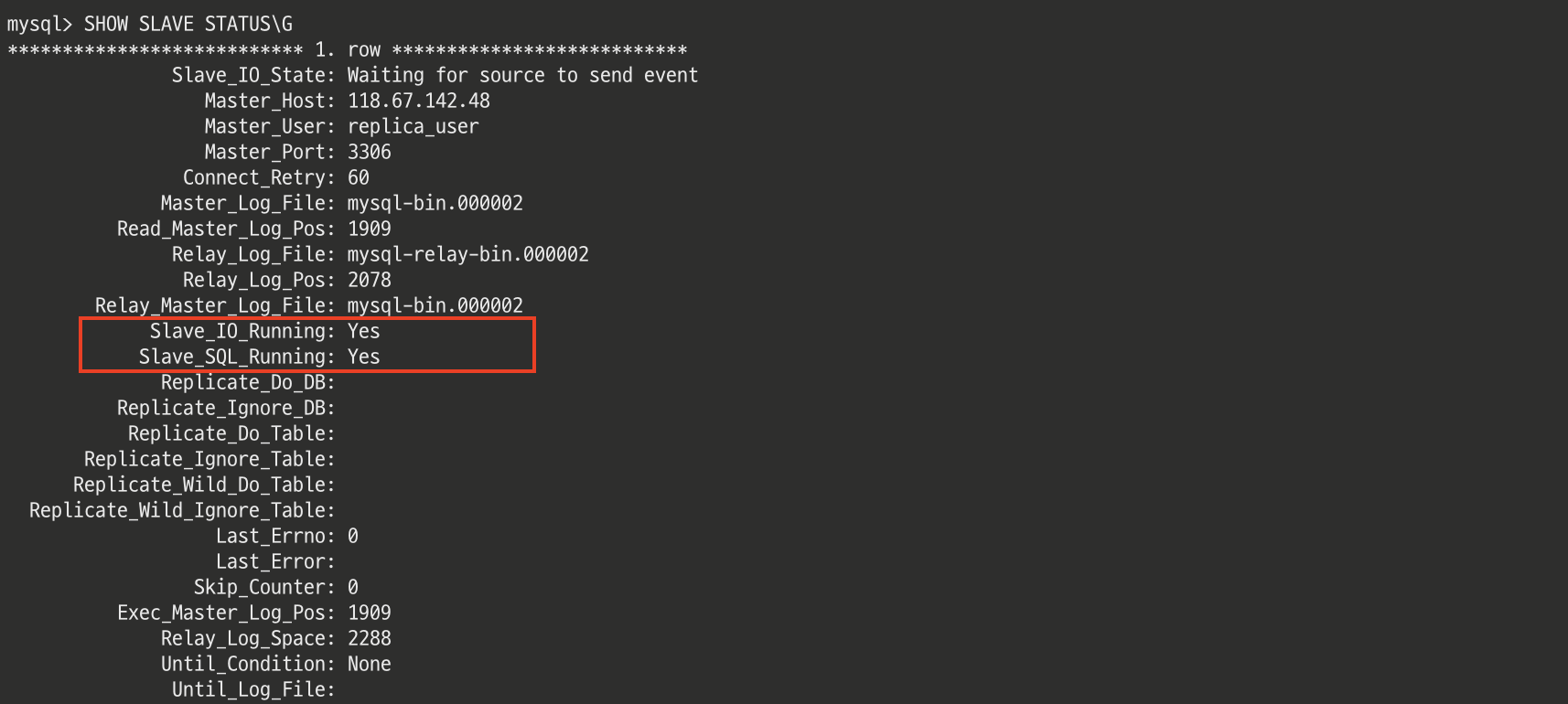
그리고 레플리카 서버 상태를 확인하면 Slave IO와 Slave SQL이 모두 정상적으로 동작하는 것을 확인할 수 있다.
테스트

소스 서버에서 상품 테이블에서 id가 1인 상품의 재고를 1,000개로 수정해줬다.

그리고 레플리카 서버에서도 정상적으로 반영된 것을 확인할 수 있다.
SpringBoot 설정
@Transactional(readOnly = true)가 붙어있는 쿼리(읽기 작업)는 소스 서버와 레플리카 서버를 번갈아서, 업데이트 작업(CUD 작업)이 포함된 경우에는 소스 서버로 연결되도록 설정해줘야 한다.
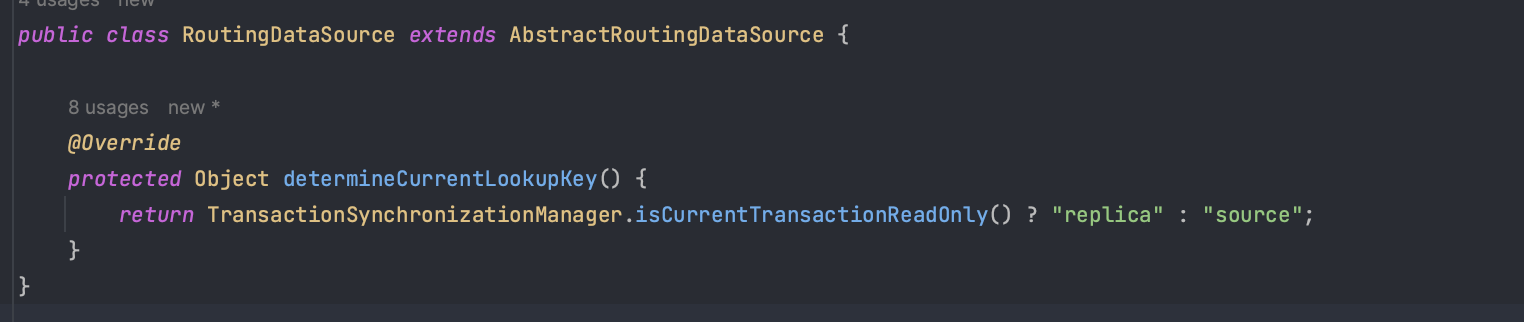
현재 한 개의 DataSource를 이용하고 있지만 이중화를 했기 때문에 두 개의 DataSource에 각각 쿼리를 보내줘야 한다. 이를 위해 AbstractRoutingDataSource 클래스에 determineCurrentLookupKey를 이용하여 Source나 Replica 중 사용할 DataSource를 라우팅할 수 있다. 위처럼 ThreadLocal 변수를 이용하여 현재 스레드에서 사용할 DataSource를 demetineCurrentLookupKey 메서드에서 정의할 수 있다.
@Configuration
public class DataSourceConfig {
private static final String SOURCE = "SOURCE";
private static final String REPLICA = "REPLICA";
@Bean
@Qualifier(SOURCE)
@ConfigurationProperties(prefix = "spring.datasource.source")
public DataSource sourceDataSource() {
return DataSourceBuilder.create()
.build();
}
@Bean
@Qualifier(REPLICA)
@ConfigurationProperties(prefix = "spring.datasource.replica")
public DataSource replicaDataSource() {
return DataSourceBuilder.create()
.build();
}
@Bean
public RoutingDataSource routingDataSource(
@Qualifier(SOURCE) DataSource sourceDataSource,
@Qualifier(REPLICA) DataSource replicaDataSource) {
HashMap<Object, Object> dataSourceMap = new HashMap<>();
dataSourceMap.put("source", sourceDataSource);
dataSourceMap.put("replica", replicaDataSource);
RoutingDataSource routingDataSource = new RoutingDataSource();
routingDataSource.setTargetDataSources(dataSourceMap);
routingDataSource.setDefaultTargetDataSource(sourceDataSource);
return routingDataSource;
}
@Bean
@Primary
public DataSource dataSource(RoutingDataSource routingDataSource) {
return new LazyConnectionDataSourceProxy(routingDataSource);
}
}위 DataSourceConfig Class를 살펴보면 데이터베이스의 소스(Source) 및 레플리카(Replica)에 대한 DataSource를 설정한다.
위에서 생성한 RoutingDataSource 클래스는 여러 데이터소스 중에서 어떤 데이터소스로 라우팅할지를 결정하는 역할을 하는데 setTargetDataSource() 메서드를 사용하여 여러 데이터소스를 Map 자료구조를 사용하여 관리하고, 위에서 오버라이딩한demetineCurrentLookupKey 메서드에서 소스 서버 및 레플리카 데이터소스를 결정한다.

Spring에서는 Transaction에 진입하는 순간에 DataSource의 Connection을 가져온다. 하지만 Multi DataSource 환경에서 트랜잭션에 진입한 이후 DataSource를 결정해야할 때 이미 트랜잭션 진입시점에 DataSource가 결정되므로 분기가 불가능하다. 따라서 트랜잭션의 LazyConnectionDataSourceProxy는 사용하면 실제 커넥션이 필요한 시점까지 커넥션 점유를 지연시켜 어느 데이터소스 커넥션을 사용할 지 결정할 수 있다. 아래를 확인하면 애플리케이션 시작 시 초기화 단계에서 각각의 커넥션 풀이 생성된 것을 확인할 수 있다.


테스트

사용자 정보를 수정하는 경우에는 당연히 readOnly가 아니기 때문에 소스 서버에서 쿼리가 실행됐다.
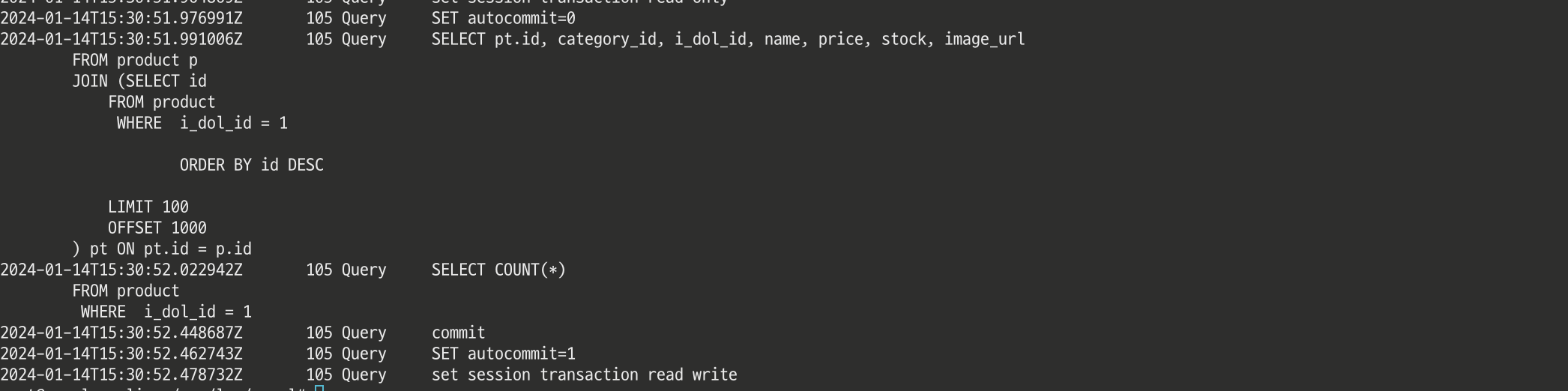
그리고 상품 목록을 조회하는 경우에는 readOnly이기 때문에 레플리카 서버에서 실행된 것을 확인할 수 있었다.
출처
[Spring] Docker, MySQL master-slave Replication + Spring Data JPA
'Java > 트러블 슈팅' 카테고리의 다른 글
| Spring WebFlux + Spring Security 적용 (0) | 2025.05.19 |
|---|---|
| nGrinder를 사용한 성능 테스트: 비관적 락 vs 분산 락 (1) | 2024.01.21 |
| 분산 락 사용 시 상위 트랜잭션이 있으면 안되는 이유 (2) | 2024.01.07 |
| 페이징 성능 개선: offset vs no offset vs covering index (0) | 2023.12.25 |
| synchronized vs Pessimistic Lock vs Distributed Lock (1) | 2023.12.21 |
- Total
- Today
- Yesterday
- 카프카
- 넥스트스탭
- nginx
- sql
- Redisson
- 낙관적 락
- 트랜잭션
- mdcfilter
- redis session
- Java
- NeXTSTEP
- nginx configuration
- 비관적 락
- transaction
- spring session
- annotation
- Kafka
- 구름톤 챌린지
- EKS
- TDD
- socket
- 람다
- jvm 메모리 구조
- Synchronized
- spring webflux
- 구름톤챌린지
- postgresql
- 분산 락
- pessimistic lock
- mysql
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |