
티스토리 뷰
ConcurrentHashMap vs synchronized HashMap, ConcurrentHashMap 구현해보기
oneny 2023. 7. 24. 19:25ConcurrentHashMap
HashMap은 싱글스레드 환경에서 사용하는 것이 좋고, 멀티스레드 환경에서는 동기화 처리를 하지 않기 때문에 thread-safe하지 않다. 이 문제를 해결하기 위해서 Collections.synchronizedMap 메서드로 원본 Map을 변환하거나 HashTable 자료구조를 사용할 수 있지만 단일 잠금 객체를 사용하기 때문에 이러한 배타적 접근방식은 성능저하를 일으킬 수 있다. 즉, 높은 동시성 하에 수많은 처리량으로 thread-safe를 원한다면, 이러한 구현은 해결책이 되지 못한다.
이러한 동기화 문제를 보완하기 위해서 Java 1.5에서 ConcurrentMap이 도입되었다. 동기화 처리를 할 때, 어떤 Entry를 조작하는 경우에 해당 Entry에 대해서만 락을 걸어 HashTable보다 데이터를 다루는 속도가 빠르다. 이러한 ConcurrentHashMap에 대해서 자세히 살펴보자.
HashMap
HashMap은 thread-safe하지 않아, 싱글 스레드 환경에서 사용하는 것이 좋다. 한편, 동기화를 처리하지 않기 때문에 HashTable과 ConcurrentHashMap보다 데이터를 탐색하는 속도는 빠르지만, 신뢰성과 안전성이 떨어진다.
HashTable
HashTable은 thread-safe하기 때문에, 멀티 스레드 환경에서 사용할 수 있다. 해당 클래스에서 데이터를 다루는 메서드(get(), put(), remove() 등)에 synchronized 키워드가 붙어 있다. 해당 키워드는 메서드를 호출하기 전에 스레드 간 동기화 락을 건다. 그래서 멀티 스레드 환경에서도 데이터의 무결성을 보장하지만 스레드 간 동기화 락을 매우 느린 동작이라는 단점이 있다.
HashMap, HashTable과 비교
| HashMap | HashTable | ConcurrentHashMap | |
| key와 value에 null 허용 | O | X | X |
| 동기화 보장(Thread-safe) | X | O | O |
| 추천 환경 | 싱글 스레드 | 멀티 스레드 | 멀티 스레드 |
싱글 스레드 환경이면 HashMap을, 멀티 스레드 환경이면 HashTable이 아닌 ConcurrentHashMap을 사용하는 것이 좋다. HashTable 보다 ConcurrentHashMap이 성능적으로 우수하기 때문이다. HashTable은 스레드간 락을 걸어 데이터를 다루는 속도가 느리다. 반면, ConcurrentHashMap은 Entry 아이템 별로 락을 걸어 데이터를 다루는 속도가 빠르다.
ConcurrentHashMap

ConcurrentHashMap 클래스는 ConcurrentMap가 있는 java.util.concurrent 패키지에 속하며 Serializable 인터페이스와 같이 구현한 클래스이다. ConcurrentHashMap의 주요 기능 중 하나는 전체 Map이 아니라 수정되는 Map의 일부만 lock을 걸어 효율적인 동시성 작업을 통해 세밀한 lock 기능을 제공한다는 것이다. 그리고 ConcurrentHashMap은 putIfAssent(), replace() 및 remove()와 같은 atomic 작업에 대한 다양한 메서드를 제공한다.
ConcurrentHashMap의 특징
- ConcurrentHashMap은 thread-safe하기 때문에 멀티스레드 환경에서 안전하게 사용할 수 있다.
- 검색(get())에는 동기화가 적용되지 않으므로 업데이트 작업(put() or remove())와 겹칠 수 있다. 그래서 검색은 가장 최근에 완료된 업데이트 작업의 결과를 반환한다.
- ConcurrentHashMap에서 객체는 동시성 수준에 따라 여러 세그먼트로 나뉘는데 기본 동시성 수준은 16이다.
- 한 스레드가 객체에 업데이트 작업을 하는 경우에는 스레드가 작업하길 원하는 특정 세그먼트를 잠가야 한다. 테이블 크기가 16이라면 한 번에 16개의 업데이트 작업까지 수행 가능하다.
- ConcurrentHashMap에는 null을 key 또는 value로 삽입할 수 없다.
ConcurrentHashMap의 생성자
ConcurrentHashMap()
ConcurrentHashMap(int initialCapacity)
ConcurrentHashMap(int initialCapacity, float loadFactor)
ConcurrentHashMap(int initialCapacity, float loadFactor, int concurrencyLevel)
ConcurrentHashMap(Map<? extends K,? extends V> m)- Concurrency Level: Map을 동시에 업데이트 작업을 수행하는 예상 스레드 라고 되어있지만, 구현시 이 값은 단순히 초기 테이블 크기를 정하는데 힌트로만 사용된다.
- Load Factor: 초기 hashTable의 크기를 설정하기 위한 용도로 쓰이며, 추후엔 ConcurrentHashMap에서는 이인자 값과 상관없이 0.75f로 동작한다.
- 예를 들어, 초기 hashTable 크기가 16이면 entry 수가 12개가 될 때 hashTable 사이즈를 16에서 32로 증가시킨다.
- Initial Capacity: 초기 용량을 결정한다. 만약 용량이 10이라면 10개의 엘리먼트를 저장할 수 있는 것을 의미한다.
ConcurrentHashMap은 기본적으로 16개의 세그먼트로 나뉘어져 있고, 각 세그먼트별로 다른 lock으로 동기화되도록 만들었다. 기본값으로는 initialCapacity는 16, loadFactor는 0.75, concurrencyLevel은 16으로 정해져 있다. concurrencyLevel을 이용하여 세그먼트 개수를 정할 수 있는데 기본적으로 16개의 세그먼트로 나뉘어져 각 세그먼트별로 다른 lock으로 동기화된다. 분리된 세그먼트 락을 갖도록 하기 때문에 멀티스레드 환경에서 전체적인 locking 방법보다 훨씬 효율적이고 뛰어난 성능을 보여준다.
ConcurrentHashMap 동작원리

ConcurrentHashMap은 위 그림처럼 각각의 Bucket 별로 동기화를 진행하기에 다른 Bucket에 속해있을 경우엔 별도의 lock없이 운용한다.
put 메서드
Map에 엘리먼트를 넣는 put(key, value)를 호출하면 ConcurrentHashMap 내부적으로 putVal(key, value, onlyIfAbsent)로 연결되는데 이에 대한 전체 소스코드는 다음과 같다. 이 소스 코드를 대략적으로 살펴보면, synchronized 키워드가 method 전체가 아닌 블록으로 선언되어 있는 것을 확인할 수 있다.
public V put(K key, V value) {
return putVal(key, value, false);
}
public V putIfAbsent(K key, V value) {
return putVal(key, value, true);
}
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh; K fk; V fv;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else if (onlyIfAbsent // check first node without acquiring lock
&& fh == hash
&& ((fk = f.key) == key || (fk != null && key.equals(fk)))
&& (fv = f.val) != null)
return fv;
else {
V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key, value);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
else if (f instanceof ReservationNode)
throw new IllegalStateException("Recursive update");
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}하나씩 코드를 살펴보도록 해보자.
1. 빈 Hash Bucket에 노드를 삽입하는 경우 Compare And Swap을 이용하여 lock을 사용하지 않고 새로운 Node를 Hash Bucket에 삽입한다.

- table은 ConcurrentHashMap에서 내부적으로 관리하는 Node의 가변 Array이며, 무한 loop를 통해 삽입될 bucket을 확인한다.
- 새로운 Node를 삽입하기 위해, tabAt()을 통해 해당 bucket을 가져오고 bucket == null로 비어있는지 확인한다.
- bucket이 비어있는 경우 casTabAt()을 통해 Node를 답고 있는 volatile 변수에 접근하고 Node와 기대값 null을 비교하여 같으면 Node를 생성해 넣고, 아니면 (1)번으로 돌아가 재시도한다.
2. 이미 Bucket에 Node가 존재하는 경우 synchronized를 이용해 하나의 thread만 접근할 수 있도록 제어하며, 서로 다른 thread가 같은 Hash Bucket에 접근할 때만 해당 block이 잠기게 된다.
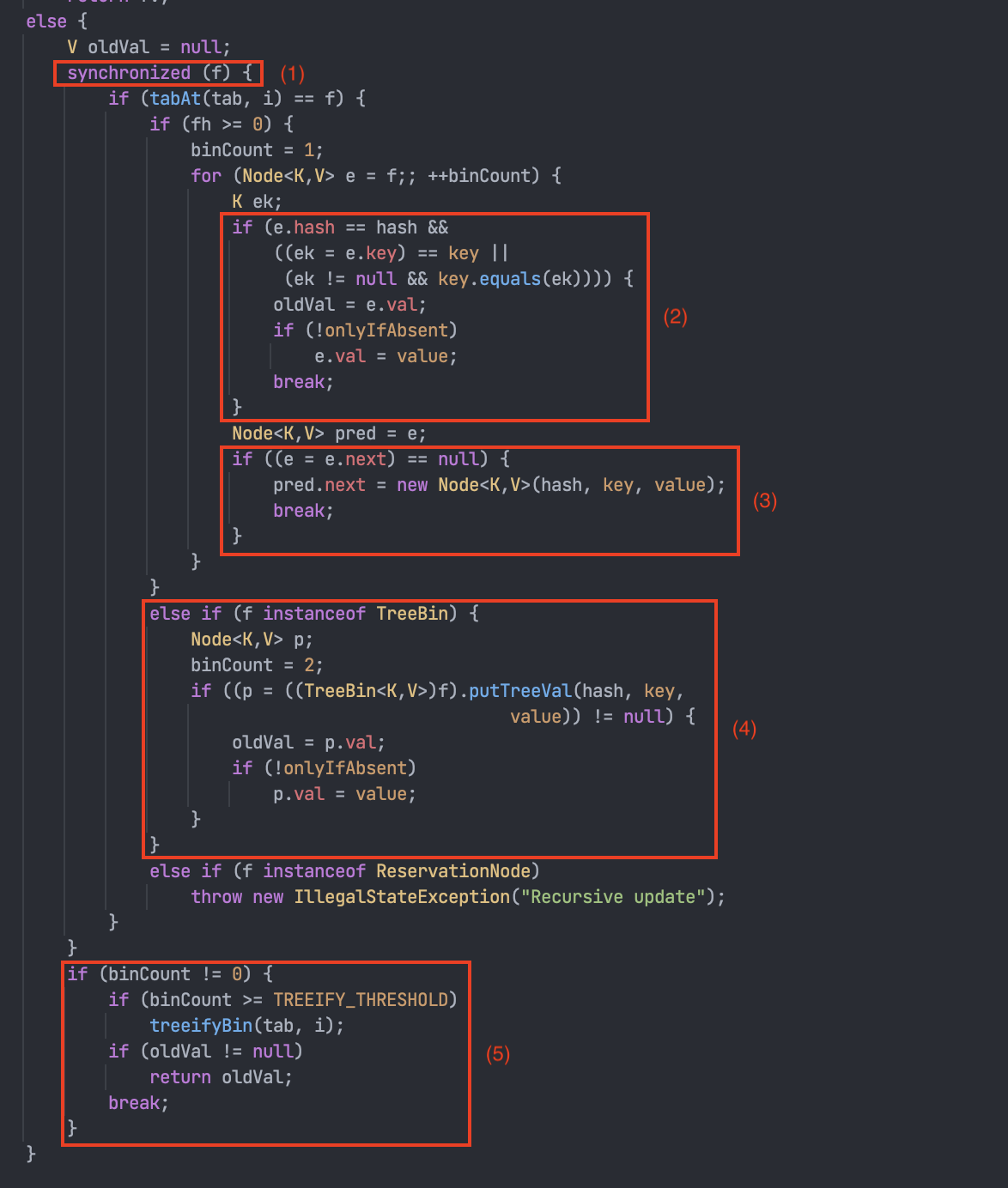
- f는 비어있지 않은 Node<K, V> type의 hash bucket을 의미하고 이것을 통해 동기화를 한다.
- 같은 key 값이 들어올 경우 새로운 Node로 교체하고, putIfAbsent(key, value)일 경우엔 값을 변경하지 않는다.
- Hash type fh 값이 양수이고 Hash 충돌일 경우엔 Seperate Chaining에 추가한다.
- Hash type fh 값이 음수일 경우엔 Tree에 추가한다.
- Hash bucket의 수 binCount에 따라 LinkedList로 운용할지 Tree로 운용할지 정한다.
synchronizedMap과 ConcurrentHashMap 비교 측정
public class CompareConcurrentHashMap {
public static void main(String[] args) throws ExecutionException, InterruptedException {
int MAP_SIZE = 2;
Map<String, Integer>[] maps = new Map[MAP_SIZE];
maps[0] = Collections.synchronizedMap(new HashMap<>());
maps[1] = new ConcurrentHashMap<>();
List<String> arrayList = new ArrayList<>();
for (int i = 0; i < 1_000_000; i++) {
String uid = UUID.randomUUID().toString();
arrayList.add(uid);
int val = (int) ((Math.random() * Integer.MAX_VALUE) + 1);
for (int j = 0; j < MAP_SIZE; j++) {
maps[j].put(uid, val);
}
}
System.out.println("========== containsKey time in multi thread ==========");
AtomicInteger[] atomicIntegers = new AtomicInteger[MAP_SIZE];
atomicIntegers[0] = new AtomicInteger(0);
atomicIntegers[1] = new AtomicInteger(0);
int availableProcessors = Runtime.getRuntime().availableProcessors();
System.out.println("availableProcessors = " + availableProcessors);
ExecutorService service = Executors.newFixedThreadPool(availableProcessors);
Future[] futures = new Future[availableProcessors];
// 쓰레드 풀 개수(프로세서 수)만큼 반복, 모든 스레드에 작업 할당
for (int i = 0; i < availableProcessors; i++) {
// 스레드 풀을 이용해 멀티 스레드로 Map의 get 메서드 호출
futures[i] = service.submit(() -> {
for (int j = 0; j < MAP_SIZE; j++) {
long st = System.currentTimeMillis();
for (int k = 0; k < arrayList.size(); k++) {
maps[j].get(arrayList.get(k));
}
// 스레드별 걸린 작업시간 측정 및 추가
atomicIntegers[j].addAndGet((int) (System.currentTimeMillis() - st));
}
});
}
// 결과값 대시
for (int i = 0; i < availableProcessors; i++) {
futures[i].get();
}
for (int i = 0; i < MAP_SIZE; i++) {
// Map 종류별로 걸린 평균시간 출력
System.out.println(maps[i].getClass().toString() + " ::: " + atomicIntegers[i].get() / availableProcessors);
}
}
}
1,000,000개의 랜덤한 데이터를 두 객체에 넣고, 모든 key를 이용해 값을 가져오는 코드이다. 멀티스레드 환경에서 동기화를 보장하면서 결과를 가져오기 때문에 동기화 성능이 중요하다. 결과를 보면 synchronizedMap이 ConcurrentHashMap에 비해 굉장히 느린 것을 확인할 수 있다. ConcurrentHashMap이 어떠한 상황에서도 SynchronizedMap보다 좋은 성능을 보여주기 때문에 멀티스레드 환경을 고려한다면 ConcurrentHashMap을 사용하는 것이 좋다.
Lock Striping 활용하여 ConcurrentHashMap 구현하기
public class MyConcurrentHashMap<K, V> {
private static final int NUM_LOCKS = 16; // 락의 개수
private final Map<K, V>[] buckets; // 각 락에 해당하는 해시 맵을 저장하는 배열
private final Object[] locks; // 락을 저장하는 배열
public MyConcurrentHashMap() {
this.buckets = new HashMap[NUM_LOCKS]; // 각 락에 해당하는 해시맵을 설정
this.locks = new Object[NUM_LOCKS]; // 락을 생성
// 각 락과 해시맵 초기화
for (int i = 0; i < NUM_LOCKS; i++) {
buckets[i] = new HashMap<>();
locks[i] = new Object();
}
}
private int getLockIndex(K key) {
// HashCode의 절대값을 락의 개수로 나누어 해당 락 인덱스를 반환
return Math.abs(key.hashCode()) % NUM_LOCKS;
}
public V get(K key) {
int lockIndex = getLockIndex(key); // key에 해당하는 락 인덱스 계산
synchronized (locks[lockIndex]) { // 해당 락을 사용하여 동기화
return buckets[lockIndex].get(key);
}
}
public void put(K key, V value) {
int lockIndex = getLockIndex(key);
synchronized (locks[lockIndex]) {
buckets[lockIndex].put(key, value);
}
}
public void remove(K key) {
int lockIndex = getLockIndex(key);
synchronized (locks[lockIndex]) {
buckets[lockIndex].remove(key);
}
}
}결과

Hash란? Java로 Hash Table 구현하기 블로그 참고하여 추가 구현
public class MyConcurrentHashMap<K, V> {
private static final int NUM_LOCKS = 16; // 락의 개수
private final LinkedList<Node<K, V>>[] buckets; // 각 락에 해당하는 해시 맵을 저장하는 배열
private final Object[] locks; // 락을 저장하는 배열
public MyConcurrentHashMap() {
this.buckets = new LinkedList[NUM_LOCKS]; // 각 락에 해당하는 해시맵을 설정
this.locks = new Object[NUM_LOCKS]; // 락을 생성
// 각 락과 해시맵 초기화
for (int i = 0; i < NUM_LOCKS; i++) {
buckets[i] = new LinkedList<>();
locks[i] = new Object();
}
}
private int getLockIndex(K key) {
// HashCode의 절대값을 락의 개수로 나누어 해당 락 인덱스를 반환
return Math.abs(key.hashCode()) % NUM_LOCKS;
}
private Node<K, V> searchKey(LinkedList<Node<K, V>> list, K key) {
if (list == null) {
return null;
}
for (Node<K, V> node : list) {
if (node.key().equals(key)) {
return node;
}
}
return null;
}
public V get(K key) {
int lockIndex = getLockIndex(key); // key에 해당하는 락 인덱스 계산
synchronized (locks[lockIndex]) { // 해당 락을 사용하여 동기화
LinkedList<Node<K, V>> list = buckets[lockIndex];
if (list == null) {
return null;
}
for (Node<K, V> node : list) {
if (node.key().equals(key)) {
return node.value();
}
}
}
return null;
}
public void put(K key, V value) {
int lockIndex = getLockIndex(key);
synchronized (locks[lockIndex]) {
LinkedList<Node<K, V>> list = buckets[lockIndex];
// 만약 해당 index에 값이 처음 입력되는 경우에는 LinkedList 생성
if (list == null) {
buckets[lockIndex] = new LinkedList<>();
}
Node<K, V> node = searchKey(list, key);
if (node == null) {
list.addLast(new Node<>(key, value));
} else {
node.value(value);
}
}
}
}
class Node<K, V> {
private K key;
private V value;
public Node(K key, V value) {
this.key = key;
this.value = value;
}
public K key() {
return key;
}
public V value() {
return value;
}
public void value(V value) {
this.value = value;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Node<?, ?> node = (Node<?, ?>) o;
return Objects.equals(key, node.key);
}
@Override
public int hashCode() {
return Objects.hash(key);
}
}Hash란? Java로 Hash Table 구현하기 작성했던 블로그 글을 토대로 체이닝 구조를 사용하고, 해당 인덱스 방에 접근하는 key별로 락을 걸어 성능이 훨씬 느리겠지만 락을 분리시키는 작업을 해봤다.
Hash란? Java로 Hash Table 구현하기
Hash Java의 hashCode 메서드를 공부하던 중 깊이있게 이해하기 위해서는 먼저 Hash에 대해 이해할 필요성을 느끼고 Hash에 대해서 먼저 정리해보기로 한다. 그러면 Hash란 무엇일까? Hash는 key와 value가
oneny.tistory.com
출처
[Java] ConcurrentHashMap은 어떻게 Thread-safe한가?
[java] ConcurrentHashMap 동기화 방식
HashMap vs HashTable vs ConcurrentHashMap
'Java > Java' 카테고리의 다른 글
| Object 클래스의 clone() 메서드 (0) | 2023.07.30 |
|---|---|
| JMX(Java Management eXtensions)와 VisualVM로 Heap Dump 들여다보기 (0) | 2023.07.24 |
| 스레드 동기화를 위한 volatile, Atomic (0) | 2023.07.22 |
| Thread 클래스(with synchronized) (0) | 2023.07.22 |
| GC(Garbage Collection), GC는 어떻게 대상 선정할까? (0) | 2023.07.17 |
- Total
- Today
- Yesterday
- 분산 락
- nginx
- pessimistic lock
- 카프카
- 구름톤 챌린지
- mdcfilter
- 넥스트스탭
- spring session
- EKS
- 비관적 락
- transaction
- mysql
- redis session
- Java
- postgresql
- 람다
- annotation
- sql
- jvm 메모리 구조
- Kafka
- TDD
- Synchronized
- 구름톤챌린지
- NeXTSTEP
- spring webflux
- socket
- Redisson
- 트랜잭션
- 낙관적 락
- nginx configuration
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |